Apache Spark je alat za analitiku podataka koji se može koristiti za obradu podataka iz HDFS-a, S3 ili drugih izvora podataka u memoriji. U ovom ćemo postu instalirati Apache Spark na Ubuntu 17.10 stroj.
Ubuntu verzija
Za ovaj ćemo vodič koristiti Ubuntu verzije 17.10 (GNU / Linux 4.13.0-38-generički x86_64).
Apache Spark dio je Hadoop ekosustava za velike podatke. Pokušajte instalirati Apache Hadoop i s njim napravite uzorak aplikacije.
Ažuriranje postojećih paketa
Da bismo započeli instalaciju za Spark, potrebno je da ažuriramo svoj stroj najnovijim dostupnim softverskim paketima. To možemo učiniti sa:
sudo apt-get update && sudo apt-get -y dist-upgradeKako se Spark temelji na Javi, moramo ga instalirati na naš stroj. Možemo koristiti bilo koju Javinu verziju iznad Jave 6. Ovdje ćemo koristiti Javu 8:
sudo apt-get -y instalirati openjdk-8-jdk-bez glavePreuzimanje datoteka Spark
Svi potrebni paketi sada postoje na našem stroju. Spremni smo za preuzimanje potrebnih Spark TAR datoteka kako bismo ih mogli početi postavljati i pokrenuti ogledni program sa Sparkom.
U ovom ćemo vodiču instalirati Iskra v2.3.0 dostupno ovdje:
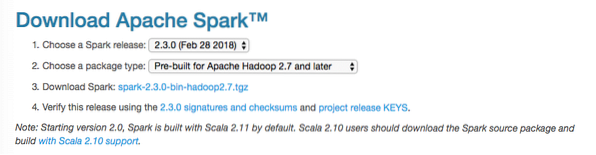
Stranica za preuzimanje iskre
Preuzmite odgovarajuće datoteke pomoću ove naredbe:
wget http: // www-us.apache.org / dist / spark / spark-2.3.0 / iskra-2.3.0-bin-hadoop2.7.tgzOvisno o brzini mreže, to može potrajati nekoliko minuta jer je datoteka velike veličine:
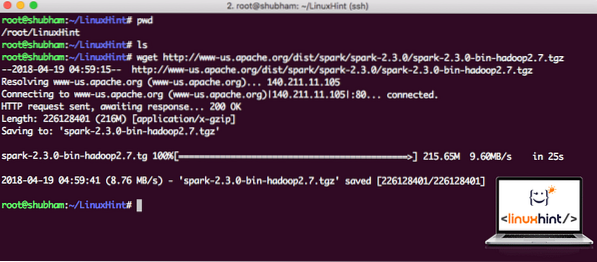
Preuzimanje Apache Sparka
Sada kada smo preuzeli TAR datoteku, možemo izdvojiti u trenutni direktorij:
katran xvzf iskra-2.3.0-bin-hadoop2.7.tgzOvo će potrajati nekoliko sekundi zbog velike veličine arhive:
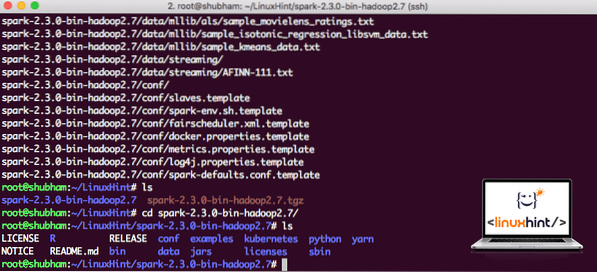
Nearhivirane datoteke u Sparku
Što se tiče nadogradnje Apache Sparka u budućnosti, to može stvoriti probleme zbog ažuriranja putanje. Ova se pitanja mogu izbjeći stvaranjem softlink-a na Spark. Pokrenite ovu naredbu da napravite softlink:
ln -s iskra-2.3.0-bin-hadoop2.7 iskraDodavanje iskre u put
Da bismo izvršili Spark skripte, sada ćemo je dodati na stazu. Da biste to učinili, otvorite datoteku bashrc:
vi ~ /.bashrcDodajte ove retke na kraj .bashrc datoteku tako da staza može sadržavati putanju izvršne datoteke Spark:
SPARK_HOME = / LinuxHint / iskraizvoz PUT = $ SPARK_HOME / bin: $ PATH
Datoteka izgleda ovako:
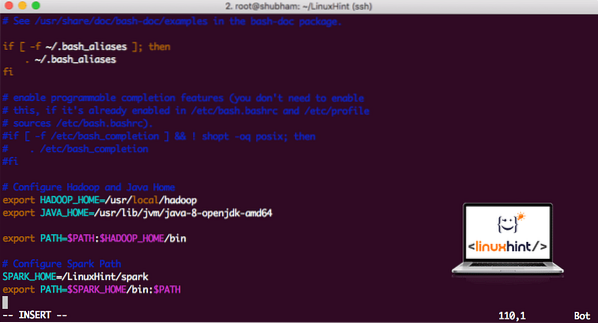
Dodavanje iskre u PUT
Da biste aktivirali ove promjene, pokrenite sljedeću naredbu za datoteku bashrc:
izvor ~ /.bashrcPokretanje ljuske Spark
Sada, kada smo odmah izvan direktorija iskre, pokrenite sljedeću naredbu da biste otvorili ljusku aparka:
./ iskra / kanta / svjećicaVidjet ćemo da je Spark ljuska otvorena sada:
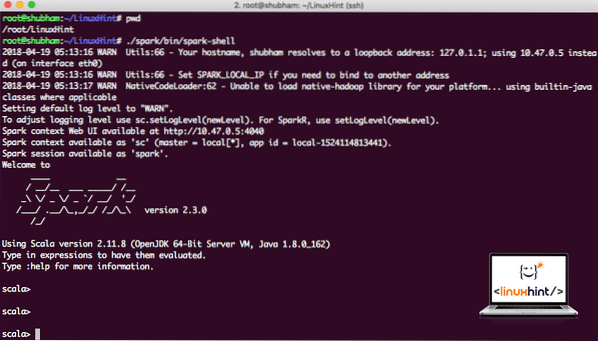
Pokretanje ljuske Spark
U konzoli možemo vidjeti da je Spark također otvorio web konzolu na portu 404. Posjetimo ga:
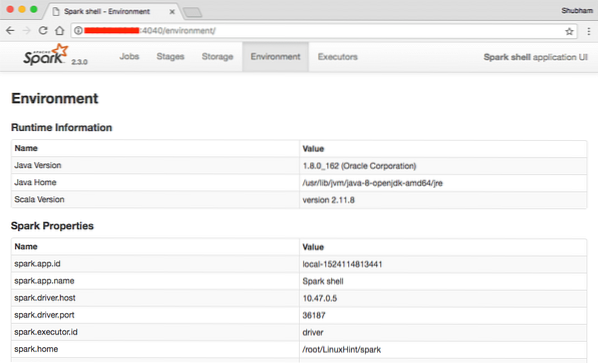
Apache Spark web konzola
Iako ćemo raditi na samoj konzoli, web okruženje je važno mjesto na koje trebate paziti kada izvršavate teške Spark poslove kako biste znali što se događa u svakom Spark Jobu koji izvršite.
Provjerite verziju ljuske Spark jednostavnom naredbom:
sc.verzijaVratit ćemo nešto poput:
res0: Niz = 2.3.0Izrada uzorka aplikacije Spark sa Scalom
Sada ćemo napraviti uzorak aplikacije Brojač riječi s Apache Sparkom. Da biste to učinili, prvo učitajte tekstualnu datoteku u Spark kontekst na ljusci Spark:
skala> var Podaci = sc.textFile ("/ root / LinuxHint / spark / README.doktor medicine")Podaci: org.apache.iskra.rdd.RDD [Niz] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] na textFile na: 24
skala>
Sad, tekst prisutan u datoteci mora se podijeliti na tokene kojima Spark može upravljati:
scala> var tokeni = Podaci.ravna karta (s => s.podjela(" "))žetoni: org.apache.iskra.rdd.RDD [String] = MapPartitionsRDD [2] na flatMap na: 25
skala>
Sada inicijalizirajte broj za svaku riječ na 1:
scala> var žetoni_1 = žetoni.karta (s => (s, 1))žetoni_1: org.apache.iskra.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] na karti na: 25
skala>
Na kraju, izračunajte učestalost svake riječi datoteke:
var sum_each = žetoni_1.reduceByKey ((a, b) => a + b)Vrijeme je da pogledamo izlaz za program. Prikupite tokene i njihovo brojanje:
scala> sum_each.prikupiti()res1: Array [(String, Int)] = Array ((paket, 1), (Za, 3), (Programi, 1), (obrada.,1), (Jer, 1), (The, 1), (stranica) (http: // spark.apache.org / dokumentacija.html).,1), (klaster.,1), (its, 1), ([run, 1), (than, 1), (APIs, 1), (have, 1), (Try, 1), (computation, 1), (through, 1 ), (nekoliko, 1), (Ovo, 2), (graf, 1), (Košnica, 2), (spremište, 1), (["Određivanje, 1), (Do, 2), (" pređa " , 1), (Jednom, 1), (["Korisno, 1), (preferiraj, 1), (SparkPi, 2), (motor, 1), (verzija, 1), (datoteka, 1), (dokumentacija ,, 1), (obrada ,, 1), (the, 24), (are, 1), (sustavi.,1), (params, 1), (ne, 1), (različito, 1), (pogledati, 2), (interaktivno, 2), (R ,, 1), (dano.,1), (if, 4), (build, 4), (when, 1), (be, 2), (Tests, 1), (Apache, 1), (thread, 1), (programi ,, 1 ), (uključujući, 4), (./ bin / run-primjer, 2), (Spark.,1), (paket.,1), (1000).count (), 1), (Verzije, 1), (HDFS, 1), (D…
skala>
Izvrsno! Uspjeli smo pokrenuti jednostavan primjer brojača riječi pomoću programskog jezika Scala s tekstualnom datotekom koja je već prisutna u sustavu.
Zaključak
U ovoj smo lekciji pogledali kako možemo instalirati i početi koristiti Apache Spark na Ubuntu 17.10 i na njemu pokrenite i primjerak aplikacije.
Ovdje pročitajte više postova temeljenih na Ubuntuu.


