Na primjer, ako želite redovito primati ažuriranja o svojim omiljenim proizvodima za ponude s popustom ili želite automatizirati postupak preuzimanja epizoda vaše omiljene sezone jednu po jednu, a web lokacija za to nema API, jedini izbor ostaje vam struganje s weba.Web struganje može biti nezakonito na nekim web mjestima, ovisno o tome dopušta li to web mjesto ili ne. Web stranice koriste „robote.txt ”za izričito definiranje URL-ova kojima nije dopušteno brisanje. Možete li provjeriti dopušta li to web mjesto dodavanjem "robota.txt ”s nazivom domene web mjesta. Na primjer, https: // www.google.com / roboti.txt
U ovom ćemo članku koristiti Python za struganje jer je vrlo jednostavan za postavljanje i upotrebu. Ima brojne ugrađene knjižnice i biblioteke trećih strana koje se mogu koristiti za struganje i organiziranje podataka. Upotrijebit ćemo dvije Python biblioteke "urllib" za dohvaćanje web stranice, a "BeautifulSoup" za raščlanjivanje web stranice za primjenu programskih operacija.
Kako funkcionira struganje weba?
Šaljemo zahtjev na web stranicu odakle želite strugati podatke. Web stranica će odgovoriti na zahtjev HTML sadržajem stranice. Zatim ovu web stranicu možemo raščlaniti na BeautifulSoup za daljnju obradu. Da bismo dohvatili web stranicu, upotrijebit ćemo knjižnicu “urllib” u Pythonu.
Urllib će preuzeti sadržaj web stranice u HTML-u. Ne možemo primijeniti niske operacije na ovoj HTML web stranici za izdvajanje sadržaja i daljnju obradu. Upotrijebit ćemo Python biblioteku "BeautifulSoup" koja će raščlaniti sadržaj i izvući zanimljive podatke.
Struganje članaka s Linuxhinta.com
Sad kad imamo ideju o tome kako mrežno struganje djeluje, odradimo malo vježbe. Pokušat ćemo ukloniti naslove članaka i poveznice s Linuxhinta.com. Dakle, otvorite https: // linuxhint.com / u vašem pregledniku.
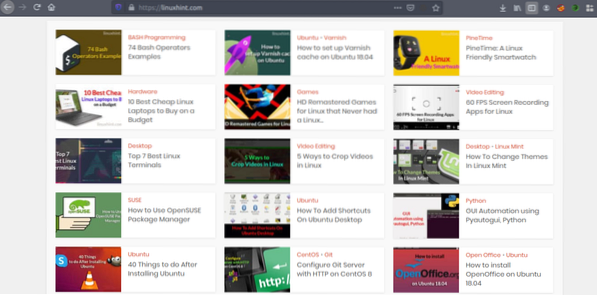
Sada pritisnite CRTL + U za prikaz HTML izvornog koda web stranice.
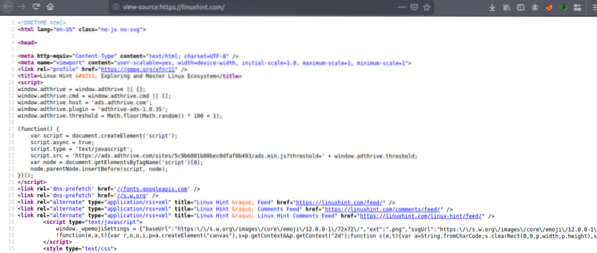
Kopirajte izvorni kod i idite na https: // htmlformatter.com / za pretvaranje koda. Nakon pretvaranja koda lako ga je pregledati i pronaći zanimljive informacije.
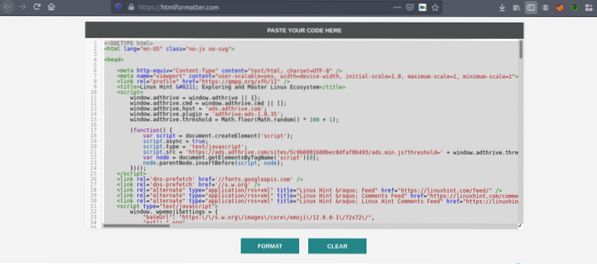
Sada opet kopirajte formatirani kod i zalijepite ga u svoj omiljeni uređivač teksta poput atoma, uzvišenog teksta itd. Sada ćemo strugati zanimljive informacije pomoću Pythona. Upišite sljedeće
// Instalirajte prekrasnu knjižnicu juha, dolazi urllibunaprijed instaliran u Pythonu
ubuntu @ ubuntu: ~ $ sudo pip3 instaliraj bs4
ubuntu @ ubuntu: ~ $ python3
Python 3.7.3 (zadano, 7. listopada 2019., 12:56:13)
[OUU 8.3.0] na Linuxu
Upišite "pomoć", "autorska prava", "krediti" ili "licenca" za više informacija.
// Uvoz urlliba>>> uvoz urllib.zahtjev
// Uvoz BeautifulSoup
>>> iz bs4 uvoza BeautifulSoup
// Unesite URL koji želite dohvatiti
>>> my_url = 'https: // linuxhint.com / '
// Zatražite URL web stranicu pomoću naredbe urlopen
>>> klijent = urllib.zahtjev.urlopen (moj_url)
// Spremite HTML web stranicu u varijablu “html_page”
>>> html_page = klijent.čitati()
// Zatvorite URL vezu nakon dohvaćanja web stranice
>>> klijent.Zatvoriti()
// raščlanite HTML web stranicu na BeautifulSoup radi struganja
>>> page_soup = BeautifulSoup (html_page, "html.parser ")
Pogledajmo sada izvorni HTML kod koji smo upravo kopirali i zalijepili kako bismo pronašli stvari koje nas zanimaju.
Vidite da je prvi članak naveden na Linuxhintu.com nazvan je "74 Bash Operators Primjeri", pronađite to u izvornom kodu. Zatvoren je između oznaka zaglavlja i njegov je kôd
title = "Primjeri 74 Bash operatora"> 74 Bash operatora
Primjeri
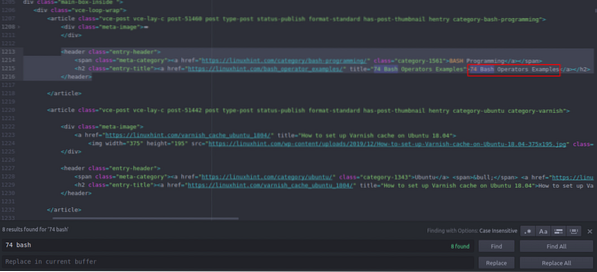
Isti se kod uvijek iznova ponavlja s promjenom samo naslova članaka i poveznica. Sljedeći članak sadrži sljedeći HTML kôd
title = "Kako postaviti predmemoriju lakova na Ubuntu 18.04 ">
Kako postaviti predmemoriju lakova na Ubuntu 18.04
Možete vidjeti da su svi članci, uključujući ova dva, zatvoreni u isti “
"I koristite istu klasu" entry-title ". Možemo koristiti funkciju "findAll" u knjižnici Beautiful Soup za pronalaženje i popis svih ""S razredom" entry-title ". Upišite sljedeće u svoju Python konzolu // Ova naredba će pronaći sve “”Elementi oznake s imenom klase
“Unos-naslov”. Izlaz će biti pohranjen u polje.
>>> članci = page_soup.findAll ("h2" ,
"class": "entry-title")
// Broj članaka nađenih na naslovnoj stranici Linuxhinta.com
>>> len (članci)
102
// Prvo izvađeno “”Element oznake koji sadrži naziv članka i vezu
>>> članci [0]
title = "74 Primjeri bash operatora">
74 Primjeri bash operatora
// Drugo izdvojeno “”Element oznake koji sadrži naziv članka i vezu
>>> članci [1]
title = "Kako postaviti predmemoriju lakova na Ubuntu 18.04 ">
Kako postaviti predmemoriju lakova na Ubuntu 18.04
// Prikazivanje samo teksta u HTML oznakama pomoću funkcije teksta
>>> članci [1].tekst
'Kako postaviti predmemoriju lakova na Ubuntu 18.04 '
”Elementi oznake s imenom klase
“Unos-naslov”. Izlaz će biti pohranjen u polje.
>>> članci = page_soup.findAll ("h2" ,
"class": "entry-title")
// Broj članaka nađenih na naslovnoj stranici Linuxhinta.com
>>> len (članci)
102
// Prvo izvađeno “”Element oznake koji sadrži naziv članka i vezu
>>> članci [0]
title = "74 Primjeri bash operatora">
74 Primjeri bash operatora
// Drugo izdvojeno “”Element oznake koji sadrži naziv članka i vezu
>>> članci [1]
title = "Kako postaviti predmemoriju lakova na Ubuntu 18.04 ">
Kako postaviti predmemoriju lakova na Ubuntu 18.04
// Prikazivanje samo teksta u HTML oznakama pomoću funkcije teksta
>>> članci [1].tekst
'Kako postaviti predmemoriju lakova na Ubuntu 18.04 '
>>> članci [0]
title = "74 Primjeri bash operatora">
74 Primjeri bash operatora
// Drugo izdvojeno “
”Element oznake koji sadrži naziv članka i vezu
>>> članci [1]
title = "Kako postaviti predmemoriju lakova na Ubuntu 18.04 ">
Kako postaviti predmemoriju lakova na Ubuntu 18.04
// Prikazivanje samo teksta u HTML oznakama pomoću funkcije teksta
>>> članci [1].tekst
'Kako postaviti predmemoriju lakova na Ubuntu 18.04 '
title = "Kako postaviti predmemoriju lakova na Ubuntu 18.04 ">
Kako postaviti predmemoriju lakova na Ubuntu 18.04
Sad kad imamo popis svih 102 HTML “
”Označi elemente koji sadrže vezu i naslov članka. Možemo izdvojiti i linkove i naslove članaka. Da biste izdvojili veze iz "”, Možemo koristiti sljedeći kod // Sljedeći će kôd izdvojiti vezu iz prvog element oznake
>>> za poveznicu u člancima [0].find_all ('a', href = True):
... ispis (veza ['href'])
..
https: // linuxhint.com / bash_operator_examples /
Sada možemo napisati for petlju koja se ponavlja kroz svaki "
Element oznake na popisu članaka i izdvojite vezu i naslov članka. >>> za i u rasponu (0,10):
… Ispis (članci [i].tekst)
... za vezu u člancima [i].find_all ('a', href = True):
… Ispis (veza ['href'] + "\ n")
..
74 Primjeri bash operatora
https: // linuxhint.com / bash_operator_examples /
Kako postaviti predmemoriju lakova na Ubuntu 18.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: SmartWatch prilagođen Linuxu
https: // linuxhint.com / pinetime_linux_smartwatch /
10 najboljih jeftinih Linux prijenosnih računala s povoljnim cijenama
https: // linuxhint.com / best_cheap_linux_laptops /
HD Remastered igre za Linux koje nikada nisu imale Linux izdanje ..
https: // linuxhint.com / hd_remastered_games_linux /
60 FPS aplikacija za snimanje zaslona za Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Primjeri bash operatora
https: // linuxhint.com / bash_operator_examples /
... odreži ..
Slično tome, ove rezultate spremate u JSON ili CSV datoteku.
Zaključak
Vaši svakodnevni zadaci nisu samo upravljanje datotekama ili izvršavanje naredbi sustava. Također možete automatizirati mrežne zadatke poput automatizacije preuzimanja datoteka ili izdvajanja podataka struganjem weba u Pythonu. Ovaj je članak bio ograničen na samo jednostavno izdvajanje podataka, ali možete obaviti ogromnu automatizaciju zadataka pomoću "urllib" i "BeautifulSoup".
>>> za poveznicu u člancima [0].find_all ('a', href = True):
... ispis (veza ['href'])
..
https: // linuxhint.com / bash_operator_examples /
… Ispis (članci [i].tekst)
... za vezu u člancima [i].find_all ('a', href = True):
… Ispis (veza ['href'] + "\ n")
..
74 Primjeri bash operatora
https: // linuxhint.com / bash_operator_examples /
Kako postaviti predmemoriju lakova na Ubuntu 18.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: SmartWatch prilagođen Linuxu
https: // linuxhint.com / pinetime_linux_smartwatch /
10 najboljih jeftinih Linux prijenosnih računala s povoljnim cijenama
https: // linuxhint.com / best_cheap_linux_laptops /
HD Remastered igre za Linux koje nikada nisu imale Linux izdanje ..
https: // linuxhint.com / hd_remastered_games_linux /
60 FPS aplikacija za snimanje zaslona za Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Primjeri bash operatora
https: // linuxhint.com / bash_operator_examples /
... odreži ..


