Grep se široko koristi u Linux sustavima kada radi na nekim datotekama, traži neki određeni obrazac i još mnogo toga. Ovoga puta koristimo naredbu grep za prikaz redaka prije i nakon podudarne ključne riječi koja se koristi u nekoj određenoj datoteci. U tu svrhu koristit ćemo oznaku "-A", "-B" i, -C "u cijelom našem vodiču s uputama. Dakle, svaki korak morate izvesti radi boljeg razumijevanja. Provjerite imate li Ubuntu 20.04 Instaliran Linux sustav.
Prvo, morate otvoriti svoj Linux terminal naredbenog retka da biste počeli raditi na grep-u. Trenutno ste u početnom direktoriju vašeg Ubuntu sustava odmah nakon otvaranja terminala naredbenog retka. Dakle, pokušajte navesti sve datoteke i mape u početnom direktoriju vašeg Linux sustava koristeći donju naredbu ls i dobit ćete sve. Vidite, u njemu su navedene neke tekstualne datoteke i neke mape.
ls
Primjer 01: Korištenje '-A' i '-B'
Iz gore prikazanih tekstualnih datoteka, pregledat ćemo neke od njih i pokušati primijeniti grep naredbu na njih. Otvorimo tekstualnu datoteku „jedan.txt "prvo koristeći popularnu naredbu" mačka "ispod:
$ mačka jedan.txt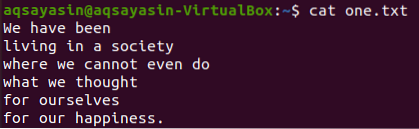
Prvo ćemo vidjeti podudaranje određenih riječi u ovoj tekstualnoj datoteci pomoću naredbe grep kao u nastavku. Riječ „mi“ tražimo u tekstualnoj datoteci „jedan“.txt ”koristeći grep upute. Izlaz prikazuje dva retka iz tekstualne datoteke u kojima je "mi".
$ grep mi jedan.txt
Dakle, u ovom ćemo primjeru prikazati retke prije i nakon podudaranja određene riječi u nekim tekstualnim datotekama. Dakle, koristeći istu tekstualnu datoteku „jedan.txt "podudarali smo se s riječju" mi "dok smo prikazivali 3 retka prije nje, kao u nastavku. Zastava "-B" znači "Prije". Izlaz prikazuje samo 2 retka prije određenog retka riječi jer datoteka nema više redaka prije retka određene riječi. Također prikazuje one retke u kojima je prisutna ta određena riječ.
$ grep -B 3 mi jedan.txt
Upotrijebimo istu ključnu riječ "mi" iz ove datoteke za prikaz 3 retka nakon retka koji imaju riječ "mi". Zastava "-A" predstavlja "Poslije". Izlaz ponovno prikazuje samo 2 retka jer nema više redaka u datoteci.
$ grep -A 3 mi jedan.txt
Dakle, upotrijebimo novu ključnu riječ koja se podudara i prikažemo retke ili retke prije i poslije retka u kojem se nalazi. Dakle, koristili smo riječ "mogu" za podudaranje. Brojevi linija u ovom su slučaju jednaki. 3 retka nakon podudarne riječi "može" prikazana su u nastavku pomoću grep naredbe.
$ grep -A 3 mogu jedan.txt
Rezultate možete vidjeti prije redaka odgovarajuće riječi pomoću ključne riječi "mogu". Suprotno tome, prikazuje samo dva retka prije retka podudarne riječi jer prije njega nema više redaka.
$ grep -B 3 može jedan.txt
Primjer 02: Korištenje '-A' i '-B'
Uzmimo drugu tekstualnu datoteku, „dvije.txt, "iz početnog direktorija i prikažite njegov sadržaj pomoću donje naredbe" mačka ".
$ mačka dva.txt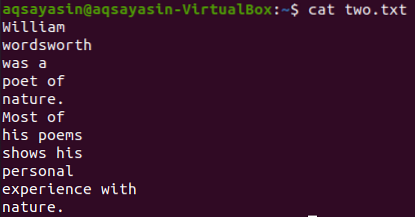
Prikažimo 5 redaka ispred riječi „Most“ iz datoteke „two“.txt ”pomoću naredbe grep. Izlaz prikazuje 5 redaka prije nego što redak sadrži određenu riječ.
$ grep -B 5 Najviše dvoje.txt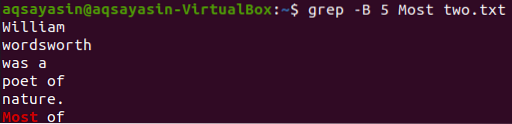
Naredba grep za prikazuje 5 redaka nakon riječi "Most" iz tekstualne datoteke "two".txt ”dat je u nastavku.
$ grep -A 5 Najviše dvoje.txt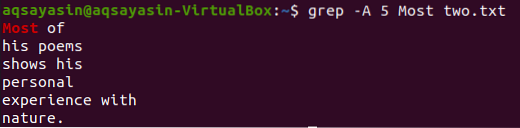
Promijenimo ključnu riječ koju ćemo pretraživati. Ovaj ćemo put upotrijebiti "od" kao ključnu riječ. Prikažite dva retka ispred riječi „od“ iz tekstualne datoteke „dva“.txt "može se izvršiti pomoću naredbe grep u nastavku. Izlaz prikazuje dva retka za ključnu riječ "od", jer dolazi dva puta u datoteku. Stoga izlaz sadrži više od 2 retka.
$ grep -B 2 od dva.txt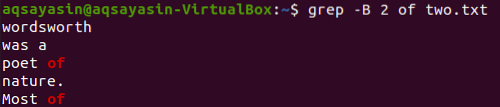
Sada se prikazuju 2 retka datoteke „dva.txt "nakon retka koji sadrži ključnu riječ" od "može se izvršiti pomoću naredbe u nastavku. Izlaz ponovno prikazuje više od 2 retka.
$ grep -Dva od dva.txt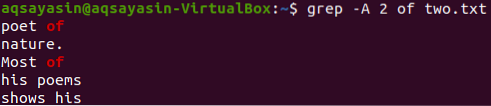
Primjer 03: Korištenje '-C'
Još jedna zastava, "-C", korištena je za prikaz redaka prije i nakon odgovarajuće riječi. Prikažimo sadržaj datoteke „jedan.txt ”pomoću naredbe cat.
$ mačka jedan.txt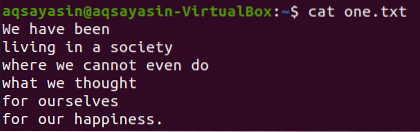
Odabrali smo „društvo“ kao ključnu riječ koja se podudara. Naredna grep naredba prikazat će 2 retka prije i 2 retka nakon retka koji u sebi sadrži riječ "društvo". Izlaz prikazuje jedan redak ispred određenog retka riječi i 2 retka nakon njega.
$ grep -C 2 društvo jedno.txt
Pogledajmo sadržaj datoteke „dva.txt ”koristeći donju naredbu mačka.
$ mačka dva.txt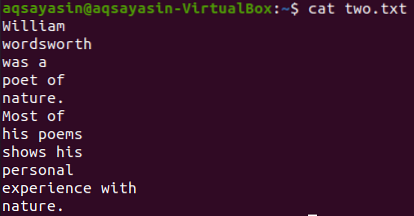
Na ovoj ilustraciji koristimo „pjesme“ kao ključnu riječ koja se podudara. Dakle, izvršite donju naredbu za ovo. Izlaz prikazuje dva retka prije i dva retka nakon odgovarajuće riječi.
$ grep -C 2 pjesme dvije.txt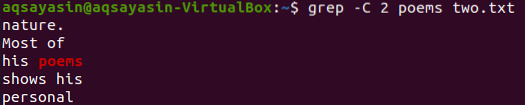
Upotrijebimo još jednu ključnu riječ iz datoteke „dva.txt ”koji se podudara. Ovaj put konzumiramo "prirodu" kao ključnu riječ. Dakle, isprobajte naredbu u nastavku dok koristite "-C" kao zastavicu koja ima ključnu riječ "priroda" iz datoteke "dva.txt ". Ovaj put, izlaz ima više od dva retka u izlazu. Budući da datoteka više puta sadrži riječ "priroda", to je razlog koji stoji iza nje. Ključna riječ "priroda", koja je prva, ima dva retka prije i dva retka iza sebe. Dok se druga podudarala s istom ključnom riječi, "priroda" ima dva retka ispred sebe, ali nema redaka nakon nje, jer je u zadnjem retku datoteke.
$ grep -C 2 pjesme dvije.txt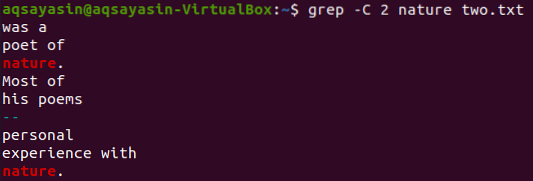
Zaključak
Uspješno prikazujemo retke prije i poslije određene riječi dok koristimo grep upute.


