Sastavljanje i pokretanje R iz naredbenog retka
Dva su načina pokretanja R programa: R skripta, koja se široko koristi i najpoželjnija je, a drugi je R CMD BATCH, to nije uobičajena naredba. Možemo ih nazvati izravno iz naredbenog retka ili bilo kojeg drugog planera poslova.
Te naredbe možete nazvati iz ljuske ugrađene u IDE, a danas RStudio IDE dolazi s alatima koji poboljšavaju ili upravljaju funkcijama R skripte i R CMD BATCH.
funkcija source () unutar R dobra je alternativa korištenju naredbenog retka. Ova funkcija također može pozvati skriptu, ali da biste koristili ovu funkciju, morate biti u R okruženju.
Ugrađeni skupovi podataka na R jeziku
Da biste popisali skupove podataka koji su ugrađeni u R, upotrijebite naredbu data (), zatim pronađite ono što želite i upotrijebite ime skupa podataka u funkciji data (). Podaci poput korisnika (ime funkcije).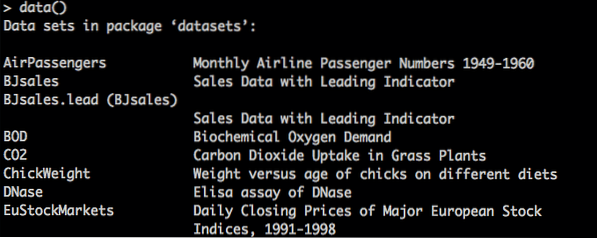
Prikaži skupove podataka u R
Znak pitanja (?) može se koristiti za traženje pomoći za skupove podataka.
Da biste provjerili postoji li sve, koristite sažetak ().
Plot () je također funkcija koja se koristi za crtanje grafova.
Stvorimo testnu skriptu i pokrenimo je. Stvoriti str1.R datoteku i spremite je u kućni direktorij sa sljedećim sadržajem:
Primjer koda:
# Jednostavan pozdrav svjetski kod u R print ("Hello World!") print (" LinuxHint ") print (5 + 6) 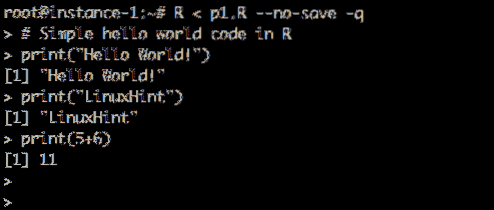
Trčanje Hello World
R Okviri podataka
Za spremanje podataka u tablice koristimo strukturu u R koja se naziva a Okvir podataka. Koristi se za popis vektora jednake duljine. Na primjer, sljedeća varijabla nm je okvir podataka koji sadrži tri vektora x, y, z:
x = c (2, 3, 5) y = c ("aa", "bb", "cc") z = c (TRUE, FALSE, TRUE) # nm je okvir podataka nm = data.okvir (n, s, b) Postoji koncept tzv UgrađenaOkviri podataka i u R-u. mtcars je jedan takav ugrađeni podatkovni okvir u R, koji ćemo upotrijebiti kao primjer za naše bolje razumijevanje. Pogledajte donji kod:
> mtcars mpg cyl disp hp drat wt… Mazda RX4 21.0 6 160 110 3.90 2.62… autobus RX4 Wag 21.0 6 160 110 3.90 2.88… Datsun 710 22.8 4 108 93 3.85 2.32…
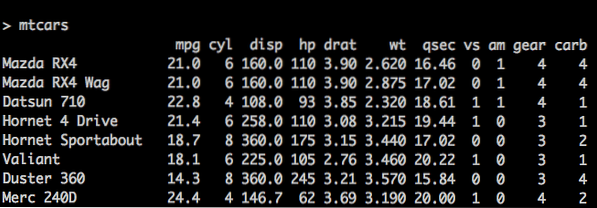
mtcars bulitin podatkovni okvir
Zaglavlje je gornji redak tablice koji sadrži nazive stupaca. Redovi podataka doniraju se svakom vodoravnom crtom; svaki redak započinje nazivom retka, a zatim slijede stvarni podaci. Član podataka u retku naziva se ćelijom.
Koordinate reda i stupca unijeli bismo u jedan kvadratni zagrada '[]' da bismo dohvatili podatke u ćeliji. Za odvajanje koordinata koristimo zarez. Redoslijed je bitan. Koordinata započinje s retkom pa zarezom, a zatim završava sa stupcem. Vrijednost ćelije 2nd red i 1sv stupac je dan kao:
> mtcars [2, 2] [1] 6
Umjesto koordinata možemo koristiti i naziv retka i stupca:
> mtcars ["Bus RX4", "mpg"] [1] 6
Nrow funkcija koristi se za pronalaženje broja redaka u podatkovnom okviru.
> nrow (mtcars) # broj redaka podataka [1] 32
ncol funkcija koristi se za pronalaženje broja stupaca u okviru podataka.
> ncol (mtcars) # broj stupaca [1] 11
R Programske petlje
Pod nekim uvjetima petlje koristimo kada želimo automatizirati neki dio koda ili želimo ponoviti slijed uputa.
Petlja za u R
Ako ove godine želimo ispisati podatke više puta.
print (zalijepi ("Godina je", 2000.)) "Godina je 2000." ispiši (zalijepi ("Godina je", 2001.)) "Godina je 2001." ispiši (zalijepi ("Godina je", 2002.) ) Ispis "Godina je 2002" (zalijepi ("Godina je", 2003.)) "Ispiši godinu (2003.) (zalijepi (" Godina je ", 2004.))" Ispiši (godina je 2004.) (zalijepi (" Godina je ", 2005.))" Godina je 2005. " Umjesto da našu izjavu ponavljamo iznova i iznova ako koristimo za petlja bit će nam puno lakše. Kao ovo:
za (godina u c (2000,2001,2002,2003,2004,2005)) print (zalijepi ("Godina je", godina)) "Godina je 2000" "Godina je 2001" "Godina je 2002. "" Godina je 2003. "" Godina je 2004. "" Godina je 2005. " Dok je Petlja u R
while (izraz) izjava
Ako je rezultat izraza TRUE, unosi se tijelo petlje. Izvodi unutar petlje se izvode i tok se vraća kako bi se ponovno procijenio izraz. Petlja će se ponavljati dok izraz ne dobije vrijednost FALSE, u tom slučaju petlja izlazi.
Primjer while Loop:
# i se u početku inicijalizira na 0 i = 0 dok (i<5) print (i) i=i+1 Output: 0 1 2 3 4
U gornjoj petlji while izraz je ja<5koja mjeri TRUE jer je 0 manje od 5. Stoga se tijelo petlje izvršava i ja je izlaz i uvećan. Važno je povećavati ja unutar petlje, tako da će u nekom trenutku nekako ispuniti uvjet. U sljedećoj petlji vrijednost ja je 1, a petlja se nastavlja. Ponavljat će se do ja jednako 5 kad je uvjet 5<5 reached loop will give FALSE and the while loop will exit.
R funkcije
Da biste stvorili funkcija koristimo direktivnu funkciju (). Točnije, oni su R objekti klase funkcija.
f <- function() ##some piece of instructions
Značajno je da se funkcije mogu prosljeđivati drugim funkcijama jer se argumenti i funkcije mogu ugnijezditi kako bi vam se omogućilo određivanje funkcije unutar druge funkcije.
Funkcije po želji mogu imati neke imenovane argumente koji imaju zadane vrijednosti. Ako ne želite zadanu vrijednost, možete postaviti njezinu vrijednost na NULL.
Neke činjenice o argumentima funkcije R:
- Argumenti prihvaćeni u definiciji funkcije formalni su argumenti
- Funkcija obrasca može vratiti popis svih formalnih argumenata funkcije
- Ne koristi svaki poziv funkcije u R sve formalne argumente
- Argumenti funkcije mogu imati zadane vrijednosti ili možda nedostaju
#Definiranje funkcije: f <- function (x, y = 1, z = 2, s= NULL)
Stvaranje modela logističke regresije s ugrađenim skupom podataka
The glm () funkcija se koristi u R kako bi se uklopila u logističku regresiju. glm () funkcija slična je lm (), ali glm () ima neke dodatne parametre. Njegov format izgleda ovako:
glm (X ~ Z1 + Z2 + Z3, obitelj = binom (link = ”logit”), podaci = mydata)
X ovisi o vrijednostima Z1, Z2 i Z3. Što znači da su Z1, Z2 i Z3 neovisne varijable, a X ovisna funkcija uključuje dodatnu obitelj parametara i ima vrijednost binom (link = “logit”) što znači da je funkcija veze logit, a distribucija vjerojatnosti regresijskog modela binom.
Pretpostavimo da imamo primjer studenta kod kojeg će dobiti upis na temelju dva rezultata ispita. Skup podataka sadrži sljedeće stavke:
- rezultat _1- Rezultat-1 rezultat
- rezultat _2- Rezultat -2 rezultat
- primljeno- 1 ako je primljeno ili 0 ako nije primljeno
U ovom primjeru imamo dvije vrijednosti 1 ako je student dobio upis i 0 ako nije dobio upis. Moramo generirati model za predviđanje da li je student dobio pristup ili ne,. Za zadani problem, prihvaćeni se smatra zavisnom varijablom, exam_1 i exam_2 smatraju se neovisnim varijablama. Za taj model dan je naš R kod
> Model_1<-glm(admitted ~ result_1 +result_2, family = binomial("logit"), data=data) Pretpostavimo da imamo dva rezultata učenika. Rezultat-1 65% i rezultat-2 90%, sada ćemo predvidjeti da student dobije pristup ili ne za procjenu vjerojatnosti studenta da dobije prijem naš R kod je kao ispod:
> unutarnji okvir<-data.frame(result_1=65,result_2=90) >predvidjeti (Model_1, in_frame, type = "response") Izlaz: 0.9894302
Gornji izlaz pokazuje nam vjerojatnost između 0 i 1. Ako je tada manje od 0.5 to znači da student nije dobio prijem. U ovom će stanju biti LAŽNO. Ako je veći od 0.5, uvjet će se smatrati ISTINITIM što znači da je student dobio upis. Moramo koristiti funkciju round () za predviđanje vjerojatnosti između 0 i 1.
R kod za to je kako je prikazano dolje:
> okrugli (predvidjeti (Model_1, in_frame, type = "response")) [/ code] Izlaz: 1
Student će dobiti upis jer je rezultat 1. Štoviše, možemo na isti način predvidjeti i druga opažanja.
Korištenje modela logističke regresije (bodovanje) s novim podacima
Po potrebi model možemo spremiti u datoteku. R kod za naš model vlaka izgledat će ovako:
model <- glm(my_formula, family=binomial(link='logit'),data=model_set)
Ovaj se model može spremiti sa:
spremi (datoteka = "naziv datoteke", datoteka_datoteke)
Datoteku možete upotrijebiti nakon spremanja, koristeći taj mir R koda:
učitavanje (datoteka = "naziv datoteke")
Za primjenu modela na nove podatke možete upotrijebiti ovaj redak koda:
skup_ modela $ pred <- predict(the_model, newdata=model_set, type="response")
BILJEŠKA: Skup_ modela ne može se dodijeliti nijednoj varijabli. Za učitavanje modela koristit ćemo funkciju load (). Nova opažanja neće ništa promijeniti u modelu. Model će ostati isti. Stari model koristimo za predviđanje novih podataka kako ne bismo ništa promijenili u modelu.
Zaključak
Nadam se da ste vidjeli kako R programiranje funkcionira na osnovni način i kako možete brzo krenuti u akciju radeći strojno učenje i kodiranje statistika s R.


