Da biste razumjeli koncept pretraživanja cijelog teksta, morate se prisjetiti znanja o pretraživanju uzoraka pomoću ključne riječi LIKE. Dakle, pretpostavimo tablicu "osoba" u "testu" baze podataka sa sljedećim zapisima.
>> ODABERI * OD osobe;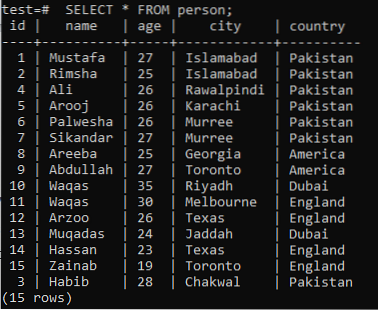
Pretpostavimo da želite dohvatiti zapise ove tablice, gdje stupac 'ime' ima znak 'i' u bilo kojoj od svojih vrijednosti. Isprobajte donji upit SELECT dok koristite klauzulu LIKE u naredbenoj ljusci. Iz donjeg rezultata možete vidjeti da imamo samo 5 zapisa za ovaj određeni znak 'i' u stupcu 'ime'.
>> ODABERI * OD osobe GDJE ime KAO '% i%';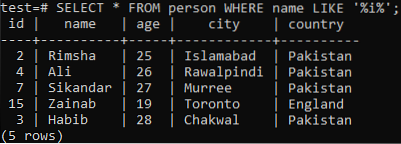
Upotreba Tvsectora:
Ponekad je korisno koristiti LIKE Keyword za brzo pretraživanje uzoraka, iako je riječ tu. Možda biste razmislili o korištenju standardnih izraza, i premda je ovo izvediva alternativa, regularni izrazi su i jaki i tromi. Imati proceduralni vektor za cijele riječi u tekstu, zavičajni opis tih riječi, mnogo je učinkovitiji način rješavanja ovog problema. Koncept cjelovitog pretraživanja teksta i tipa podataka tsvector stvoren je da odgovori na njega. Postoje dvije metode u PostgreSQL-u koje rade upravo ono što mi želimo:
- To_tvsector: Koristi se za izradu popisa tokena (ts znači za "pretraživanje teksta").
- To_tsquery: Koristi se za traženje vektora radi učestalosti određenih pojmova ili fraza.
Primjer 01:
Počnimo s jednostavnom ilustracijom stvaranja vektora. Pretpostavimo da želite napraviti vektor za niz: „Neki ljudi imaju kovrčavu smeđu kosu pravilnim četkanjem.". Dakle, morate napisati funkciju to_tvsector () zajedno s ovom rečenicom u zagradama SELECT upita kao što je priloženo u nastavku. Iz donjeg izlaza možete vidjeti da bi donio vektor referenci (položaja datoteke) za svaki token, a također i tamo gdje se pojmovi s malo konteksta, poput članaka (i) i veznika (i, ili), namjerno ignoriraju.
>> ODABERITE to_tsvector ('Neki ljudi imaju kovrčave smeđe dlake pravilnim četkanjem');
Primjer 02:
Pretpostavimo da imate dva dokumenta s po nekim podacima u oba. Da bismo pohranili ove podatke, sada ćemo koristiti stvarni primjer generiranja tokena. Pretpostavimo da ste stvorili tablicu 'Podaci' u vašoj bazi podataka 'test' s nekoliko stupaca u njoj koristeći upit CREATE TABLE u nastavku. Ne zaboravite u njemu stvoriti stupac tipa TVSECTOR pod nazivom 'token'. Iz donjeg rezultata možete pogledati tablicu koja je stvorena.
>> IZRADI PODATKE U TABELI (Id PRVENI PRIRODNI KLJUČ, info TEKST, token TSVECTOR);
Sada se pretvara da u ovu tablicu dodamo sveukupne podatke oba dokumenta. Dakle, pokušajte donju naredbu INSERT u ljusci naredbenog retka da biste to učinili. Napokon, zapisi iz oba dokumenta uspješno su dodani u tablicu 'Podaci'.
>> INSERT INTO Data (info) VRIJEDNOSTI ('Dvije pogreške nikada ne mogu ispraviti jednu.'), (' On je taj koji može igrati nogomet.'), (' Mogu li igrati ulogu u ovome?'), (' Ne može se razumjeti bol u čovjeku '), (' Donesite breskvu u svoj život);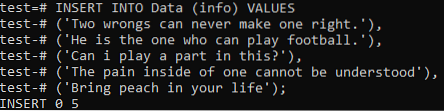
Sada morate kolonizirati stupac tokena oba dokumenta s njihovim određenim vektorom. U konačnici, jednostavni UPDATE upit ispunit će stupac žetona odgovarajućim vektorom za svaku datoteku. Dakle, morate izvršiti navedeni donji upit u naredbenoj ljusci da biste to učinili. Rezultat pokazuje da je ažuriranje konačno izvršeno.
>> AŽURIRANJE podataka f1 SET token = to_tsvector (f1.info) IZ podataka f2;
Sad kad smo sve to postavili na mjesto, vratimo se na skeniranje ilustracije "može li netko". Kako to_tsquery s operatorom AND, kao što je prethodno rečeno, ne pravi razliku između mjesta datoteka u datotekama, kao što je prikazano iz rezultata navedenog u nastavku.
>> ODABERITE Id, podatke IZ podataka WHERE token @@ to_tsquery ('can & one');
Primjer 04:
Da bismo pronašli riječi koje su "jedna do druge", pokušat ćemo isti upit s '<->'operater. Promjena je prikazana u donjem izlazu.
>> ODABERITE Id, informacije IZ podataka WHERE token @@ to_tsquery ('can <-> jedan');
Evo primjera da nema neposredne riječi pored druge.
>> ODABERITE Id, informacije IZ podataka WHERE token @@ to_tsquery ('one <-> bol');
Primjer 05:
Pronaći ćemo riječi koje nisu odmah jedna pored druge pomoću broja u operatoru udaljenosti za referenciranje udaljenosti. Blizina između "dovesti" i "života" je 4 riječi, osim prikazane slike.
>> ODABERI * IZ podataka GDJE token @@ to_tsquery ('donijeti <4> život');
Da bi se provjerila blizina između riječi za gotovo 5 riječi, dodaje se u nastavku.
>> ODABERI * IZ podataka WHERE token @@ to_tsquery ('pogrešno <5> pravo');
Zaključak:
Na kraju, napravili ste sve jednostavne i komplicirane primjere pretraživanja cijelog teksta pomoću operatora i funkcija To_tvsector i to_tsquery.


