Pande .read_csv
Već sam razgovarao o nekoj povijesti i korištenju pandi knjižnice Python. pandas je dizajniran iz potrebe za učinkovitom bibliotekom za analizu i manipulaciju financijskim podacima za Python. Kako bi učitali podatke za analizu i manipulaciju, pande pružaju dvije metode, DataReader i read_csv. Ovdje sam pokrio prvo. Potonje je predmet ovog vodiča.
.read_csv
Postoji velik broj besplatnih spremišta podataka na mreži koja uključuju informacije o raznim poljima. Neke od tih resursa uključio sam u odjeljak referenci u nastavku. Budući da sam pokazao ugrađene API-je za učinkovito povlačenje financijskih podataka ovdje, upotrijebit ću drugi izvor podataka u ovom vodiču.
Podaci.gov nudi ogroman izbor besplatnih podataka o svemu, od klimatskih promjena do U.S. statistika proizvodnje. Preuzeo sam dva skupa podataka za upotrebu u ovom vodiču. Prva je srednja dnevna maksimalna temperatura za Bay County na Floridi. Ovi su podaci preuzeti s U-a.S. Priručnik o klimatskoj otpornosti za razdoblje od 1950. do danas.
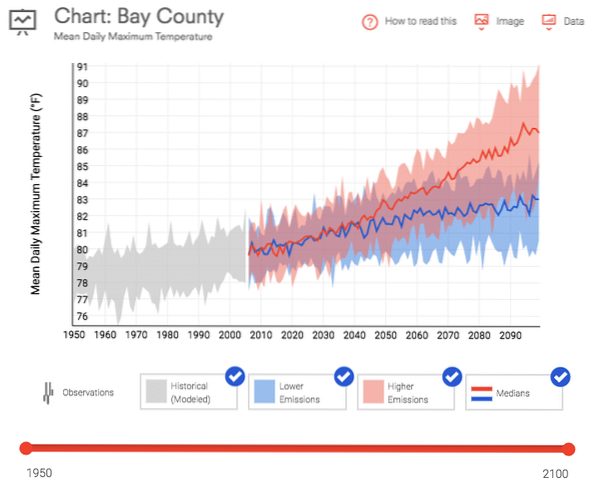
Drugo je istraživanje robnog toka koje mjeri način i obujam uvoza u zemlju tijekom petogodišnjeg razdoblja.

Obje veze za ove skupove podataka nalaze se u odjeljku referenci u nastavku. The .read_csv metoda, kao što je jasno iz naziva, učitat će ove podatke iz CSV datoteke i instancirati a DataFrame izvan tog skupa podataka.
Upotreba
Svaki put kada koristite vanjsku knjižnicu, morate reći Pythonu da je treba uvesti. Ispod je redak koda koji uvozi biblioteku panda.
uvoziti pande kao pdOsnovna upotreba .read_csv metoda je dolje. Ovo instancira i popunjava a DataFrame df s podacima u CSV datoteci.
df = pd.read_csv ('12005-godišnja-hist-obs-tasmax.csv ')Dodavanjem još nekoliko redaka možemo pregledati prvih i zadnjih 5 redaka iz novostvorenog DataFramea.
df = pd.read_csv ('12005-godišnja-hist-obs-tasmax.csv ')ispis (df.glava (5))
ispis (df.rep (5))

Kôd je učitao stupac za godinu, srednju dnevnu temperaturu u Celzijusu (tasmax) i konstruirao shemu indeksiranja temeljenu na 1 koja se uvećava za svaki redak podataka. Također je važno napomenuti da se zaglavlja popunjavaju iz datoteke. Uz osnovnu uporabu gore predstavljene metode, zaključuje se da su zaglavlja u prvom retku CSV datoteke. To se može promijeniti prenošenjem različitog skupa parametara u metodu.
Parametri
Naveo sam vezu do pandi .read_csv dokumentaciju u referencama u nastavku. Postoji nekoliko parametara koji se mogu koristiti za promjenu načina čitanja i formatiranja podataka u DataFrame.

Postoji popriličan broj parametara za .read_csv metoda. Većina nije potrebna, jer će većina skupova podataka koje preuzmete imati standardni format. To su stupci u prvom redu i graničnik zarezom.
Postoji nekoliko parametara koje ću istaknuti u vodiču jer mogu biti korisni. Opsežnije istraživanje može se preuzeti sa stranice dokumentacije.
index_col
index_col je parametar koji se može koristiti za označavanje stupca koji sadrži indeks. Neke datoteke mogu sadržavati indeks, a neke ne. U našem prvom skupu podataka, dopustio sam pythonu da stvori indeks. To je standard .read_csv ponašanje.
U naš drugi skup podataka uključen je indeks. Kôd u nastavku učitava DataFrame s podacima u CSV datoteci, ali umjesto da stvara inkrementalni indeks temeljen na cijelim brojevima, koristi stupac SHPMT_ID uključen u skup podataka.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ')ispis (df.glava (5))
ispis (df.rep (5))
Iako ovaj skup podataka koristi istu shemu za indeks, drugi skupovi podataka mogu imati korisniji indeks.
nrows, skiprows, usecols
S velikim skupovima podataka možda ćete htjeti učitati samo odjeljke podataka. The nrows, skiprows, i usecols parametri će vam omogućiti rezanje podataka uključenih u datoteku.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ', nrows = 50)ispis (df.glava (5))
ispis (df.rep (5))
Dodavanjem nrows parametar s cijelom vrijednosti 50, .tail call sada vraća linije do 50. Ostali podaci u datoteci nisu uvezeni.
ispis (df.glava (5))
ispis (df.rep (5))
Dodavanjem skiprows parametar, naš .glava col ne prikazuje početni indeks 1001 u podacima. Budući da smo preskočili redak zaglavlja, novi podaci izgubili su zaglavlje i indeks na temelju podataka datoteke. U nekim slučajevima možda je bolje podatke razrezati u a DataFrame nego prije učitavanja podataka.

The usecols je koristan parametar koji vam omogućuje uvoz samo podskupa podataka po stupcima. Može mu se proslijediti nulti indeks ili popis nizova s imenima stupaca. Upotrijebio sam donji kod za uvoz prva četiri stupca u naš novi DataFrame.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3])
ispis (df.glava (5))
ispis (df.rep (5))
Od našeg novog .glava nazovite, naš DataFrame sada sadrži samo prva četiri stupca iz skupa podataka.
motor
Posljednji parametar koji bi mi dobro došao u nekim skupovima podataka je motor parametar. Možete koristiti ili mehanizam zasnovan na C ili kôd zasnovan na Pythonu. C motor prirodno će biti brži. To je važno ako uvozite velike skupove podataka. Prednosti raščlanjivanja Pythona skup su bogatijih značajki. Ova pogodnost može značiti manje ako učitavate velike podatke u memoriju.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ',index_col = 'SHIPMT_ID', motor = 'c')
ispis (df.glava (5))
ispis (df.rep (5))
Pratiti
Postoji nekoliko drugih parametara koji mogu proširiti zadano ponašanje .read_csv metoda. Mogu se naći na stranici dokumenata na koju sam se pozvao u nastavku. .read_csv korisna je metoda za učitavanje skupova podataka u pande za analizu podataka. Budući da mnogi besplatni skupovi podataka na Internetu nemaju API-je, ovo će se pokazati najkorisnijim za aplikacije izvan financijskih podataka u kojima postoje robusni API-ji za uvoz podataka u pande.
Reference
https: // pande.pydata.org / pandas-docs / stable / generated / pandas.read_csv.html
https: // www.podaci.vlada /
https: // set alata.klima.gov / # istraživač klime
https: // www.popis.gov / econ / cfs / pums.html


