U ovoj lekciji o Strojnom učenju s scikit-learnom naučit ćemo razne aspekte ovog izvrsnog Python paketa koji nam omogućuje primjenu jednostavnih i složenih mogućnosti strojnog učenja na raznolike skupove podataka zajedno sa funkcionalnostima za testiranje hipoteze koju utvrdimo.
Paket scikit-learn sadrži jednostavne i učinkovite alate za primjenu pretraživanja podataka i analize podataka na skupovima podataka i ti su algoritmi dostupni za primjenu u različitim kontekstima. To je paket otvorenog koda dostupan pod BSD licencom, što znači da ovu knjižnicu možemo koristiti čak i komercijalno. Izgrađen je na vrhu matplotliba, NumPy-a i SciPy-a, tako da je svestrane prirode. Koristit ćemo Anacondu s Jupyterovom bilježnicom kako bismo predstavili primjere u ovoj lekciji.
Što nudi scikit-learn?
Knjižnica scikit-learn usredotočena je u potpunosti na modeliranje podataka. Imajte na umu da u scikit-learnu nisu prisutne glavne funkcije kada je riječ o učitavanju, manipulaciji i sažimanju podataka. Evo nekoliko popularnih modela koje nam nudi scikit-learn:
- Skupljanje grupirati označene podatke
- Skupovi podataka pružiti skupove testnih podataka i istražiti ponašanja modela
- Unakrsna provjera valjanosti za procjenu izvedbe nadziranih modela na neviđenim podacima
- Metode ansambla kombiniranju predviđanja više nadziranih modela
- Izdvajanje značajke definiranju atributa u slikovnim i tekstualnim podacima
Instalirajte Python scikit-learn
Samo napomenu prije početka instalacijskog postupka, za ovu lekciju koristimo virtualno okruženje koje smo napravili sljedećom naredbom:
python -m virtualenv scikitizvor scikit / bin / aktiviraj
Jednom kada je virtualno okruženje aktivno, možemo instalirati biblioteku panda unutar virtualne env tako da se mogu izvršiti primjeri koje sljedeći kreiramo:
pip instalirati scikit-learnIli možemo koristiti Conda za instalaciju ovog paketa pomoću sljedeće naredbe:
conda instalirati scikit-learnOtprilike ovako vidimo kad izvršimo gornju naredbu:

Kada se instalacija završi s Condom, moći ćemo koristiti paket u našim Python skriptama kao:
uvoz sklearnPočnimo koristiti scikit-learn u našim skriptama za razvoj sjajnih algoritama strojnog učenja.
Uvoz skupova podataka
Jedna od zgodnih stvari s scikit-learnom je da dolazi s unaprijed učitanim skupovima podataka s kojima je lako brzo započeti. Skupovi podataka su iris i znamenke baze podataka za klasifikaciju i cijene bostonskih kuća skup podataka za tehnike regresije. U ovom ćemo odjeljku pogledati kako učitati i početi koristiti skup podataka irisa.
Da bismo uvezli skup podataka, prvo moramo uvesti ispravan modul nakon čega slijedi zadržavanje skupa podataka:
iz skupova podataka za uvoz sklearniris = skupovi podataka.load_iris ()
znamenke = skupovi podataka.znamenke_učitavanja ()
znamenke.podaci
Jednom kada pokrenemo gornji isječak koda, vidjet ćemo sljedeći izlaz:

Sav se izlaz uklanja za kratkoću. Ovo je skup podataka koji ćemo uglavnom koristiti u ovoj lekciji, ali većina koncepata može se primijeniti na općenito sve skupove podataka.
Samo je zabavna činjenica znati da u sustavu Windows postoji više modula scikit ekosustav, od kojih je jedan naučiti koristi se za algoritme strojnog učenja. Pogledajte ovu stranicu za mnoge druge prisutne module.
Istraživanje skupa podataka
Sad kad smo u skriptu uvezli osigurani skup podataka znamenki, trebali bismo početi prikupljati osnovne informacije o skupu podataka i to ćemo ovdje učiniti. Evo osnovnih stvari koje biste trebali istražiti dok tražite informacije o skupu podataka:
- Ciljane vrijednosti ili oznake
- Atribut opisa
- Ključevi dostupni u danom skupu podataka
Napišimo kratki isječak koda kako bismo iz našeg skupa podataka izdvojili gornje tri informacije:
print ('Cilj:', znamenke.cilj)print ('Tipke:', znamenke.tipke ())
print ('Opis:', znamenke.DESCR)
Jednom kada pokrenemo gornji isječak koda, vidjet ćemo sljedeći izlaz:
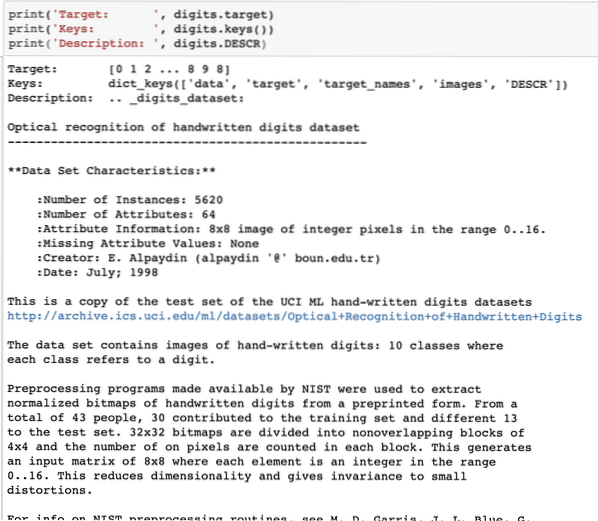
Imajte na umu da varijabilne znamenke nisu jednostavne. Kada smo ispisali skup podataka s znamenkama, on je zapravo sadržavao numpy-ove nizove. Vidjet ćemo kako možemo pristupiti tim nizovima. Za to uzmite u obzir tipke dostupne u primjerku znamenki koje smo ispisali u posljednjem isječku koda.
Započet ćemo dobivanjem oblika podataka niza, a to su redovi i stupci koje niz ima. Za to prvo moramo dobiti stvarne podatke, a zatim dobiti njihov oblik:
digits_set = znamenke.podaciispis (set_znamenki.oblik)
Jednom kada pokrenemo gornji isječak koda, vidjet ćemo sljedeći izlaz:

To znači da u našem skupu podataka imamo 1797 uzoraka, zajedno sa 64 podatkovne značajke (ili stupce). Također, imamo i neke ciljne oznake koje ćemo ovdje vizualizirati uz pomoć matplotliba. Evo isječka koda koji nam pomaže u tome:
uvoz matplotlib.pyplot kao plt# Spojite slike i ciljne naljepnice kao popis
images_and_labels = list (zip (znamenke.slike, znamenke.cilj))
za indeks, (slika, naljepnica) u enumerate (images_and_labels [: 8]):
# inicijalizirajte podplotu od 2X4 na i + 1-om položaju
plt.podzaplet (2, 4, indeks + 1)
# Ne treba crtati nijednu os
plt.os (isključeno)
# Prikaži slike u svim podplotama
plt.imshow (slika, cmap = plt.cm.grey_r, interpolacija = 'najbliže')
# Dodajte naslov u svaku parcelu
plt.naslov ('Trening:' + str (oznaka))
plt.pokazati()
Jednom kada pokrenemo gornji isječak koda, vidjet ćemo sljedeći izlaz:

Primijetite kako smo zipirali dva NumPy polja zajedno prije nego što smo ih ucrtali u mrežu 4 x 2 bez ikakvih podataka o osi. Sada smo sigurni u informacije koje imamo o skupu podataka s kojim radimo.
Sad kad znamo da imamo 64 značajke podataka (što je inače puno značajki), izazovno je vizualizirati stvarne podatke. Ipak imamo rješenje za to.
Analiza glavne komponente (PCA)
Ovo nije vodič o PCA-u, ali dajmo malu ideju o tome što je to. Kao što znamo da za smanjenje broja značajki iz skupa podataka imamo dvije tehnike:
- Eliminacija značajke
- Izdvajanje značajke
Iako se prva tehnika suočava s problemom izgubljenih značajki podataka čak i kad su mogle biti važne, druga tehnika ne pati od problema kao uz pomoć PCA, mi konstruiramo nove značajke podataka (manje u broju) gdje kombiniramo ulazne varijable na takav način da možemo izostaviti „najmanje važne“ varijable, a da pritom zadržimo najvrjednije dijelove svih varijabli.
Kao što se i očekivalo, PCA nam pomaže smanjiti visokodimenzionalnost podataka što je izravan rezultat opisa predmeta pomoću mnogih značajki podataka. Ne samo znamenke, već i mnogi drugi praktični skupovi podataka imaju velik broj značajki koje uključuju financijske institucionalne podatke, podatke o vremenu i ekonomiji za regiju itd. Kada izvodimo PCA na skupu podataka s znamenkama, naš će cilj biti pronaći samo dvije značajke koje imaju većinu karakteristika skupa podataka.
Napišimo jednostavan isječak koda za primjenu PCA na skup podataka znamenki kako bismo dobili naš linearni model od samo 2 značajke:
od sklearn.razgradnja uvoz PCAfeature_pca = PCA (n_komponente = 2)
smanjen_datan_random = obilježje_pca.fit_transform (znamenke.podaci)
model_pca = PCA (n_komponente = 2)
smanjena_podataka_pca = model_pca.fit_transform (znamenke.podaci)
smanjena_podataka_pca.oblik
ispis (smanjeni_podatci_random)
ispis (smanjena_podataka_pca)
Jednom kada pokrenemo gornji isječak koda, vidjet ćemo sljedeći izlaz:
[[-1.2594655 21.27488324][7.95762224 -20.76873116]
[6.99192123 -9.95598191]
..
[10.8012644 -6.96019661]
[-4.87210598 12.42397516]
[-0.34441647 6.36562581]]
[[-1.25946526 21.27487934]
[7.95761543 -20.76870705]
[6.99191947 -9.9559785]
..
[10.80128422 -6.96025542]
[-4.87210144 12.42396098]
[-0.3443928 6.36555416]]
U gornjem kodu spominjemo da su nam potrebne samo dvije značajke za skup podataka.
Sad kad imamo dobro znanje o našem skupu podataka, možemo odlučiti kakve algoritme strojnog učenja možemo primijeniti na njega. Poznavanje skupa podataka važno je jer na taj način možemo odlučiti koje se informacije mogu iz njega izvući i s kojim algoritmima. Također nam pomaže da testiramo hipotezu koju utvrdimo dok predviđamo buduće vrijednosti.
Primjena k-znači klasteriranje
Algoritam k-znači klasteriranja jedan je od najlakših algoritama klasteriranja za nenadgledano učenje. U ovom klasteriranju imamo nekoliko slučajnih brojeva klastera i svoje podatkovne točke klasificiramo u jedan od tih klastera. Algoritam k-znači pronaći će najbliži klaster za svaku od zadanih podatkovnih točaka i dodijeliti tu podatkovnu točku tom klasteru.
Jednom kada je klasteriranje završeno, središte klastera se preračunava, točkama podataka dodjeljuju se novi klasteri ako dođe do promjena. Taj se postupak ponavlja sve dok se podatkovne točke ne prestanu mijenjati na tamošnjim klasterima kako bi se postigla stabilnost.
Jednostavno primijenimo ovaj algoritam bez ikakve prethodne obrade podataka. Za ovu strategiju isječak koda bit će prilično jednostavan:
iz sklearn klastera za uvozk = 3
k_means = klaster.KMeans (k)
# odgovarajući podatak
k_znači.stane (znamenke.podaci)
# rezultati ispisa
ispis (k_znači.oznake _ [:: 10])
ispis (znamenke.cilj [:: 10])
Jednom kada pokrenemo gornji isječak koda, vidjet ćemo sljedeći izlaz:
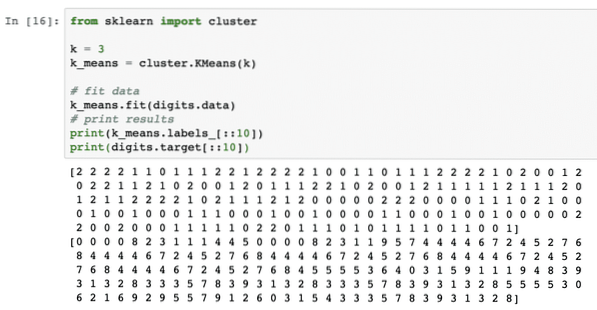
U gornjem izlazu možemo vidjeti različite klastere koji su osigurani za svaku točku podataka.
Zaključak
U ovoj smo lekciji pogledali izvrsnu biblioteku strojnog učenja, scikit-learn. Saznali smo da je u obitelji scikit dostupno mnogo drugih modula i primijenili smo jednostavni algoritam k-znači na ponuđeni skup podataka. Postoji mnogo više algoritama koji se mogu primijeniti na skup podataka, osim k-znači klasteriranja koje smo primijenili u ovoj lekciji, potičemo vas da to učinite i podijelite svoje rezultate.
Molimo podijelite svoje povratne informacije o lekciji na Twitteru s @sbmaggarwal i @LinuxHint.


