Instaliranje Tesseract OCR u Linux
Tesseract OCR dostupan je prema zadanim postavkama na većini Linux distribucija. Možete ga instalirati u Ubuntu pomoću naredbe u nastavku:
$ sudo apt instalirati tesseract-ocrDostupne su detaljne upute za ostale distribucije ovdje. Iako je Tesseract OCR prema zadanim postavkama dostupan u spremištima mnogih Linux distribucija, preporučuje se instaliranje najnovije verzije s gore spomenute veze radi veće preciznosti i raščlanjivanja.
Instaliranje podrške za dodatne jezike u Tesseract OCR
Tesseract OCR uključuje podršku za otkrivanje teksta na više od 100 jezika. Međutim, podršku za otkrivanje teksta na engleskom jeziku dobivate samo uz zadanu instalaciju u Ubuntuu. Da biste dodali podršku za raščlanjivanje dodatnih jezika u Ubuntuu, pokrenite naredbu u sljedećem formatu:
$ sudo apt instalirati tesseract-ocr-hinGornja naredba dodati će podršku za hindski jezik Tesseract OCR-u. Ponekad bolju točnost i rezultate možete dobiti instaliranjem podrške za jezične skripte. Na primjer, instaliranje i korištenje tesseract paketa za Devanagari skriptu "tesseract-ocr-script-deva" dalo mi je puno preciznije rezultate od korištenja paketa "tesseract-ocr-hin".
U Ubuntuu možete pronaći ispravna imena paketa za sve jezike i skripte pokretanjem naredbe u nastavku:
$ apt-cache search tesseract-Nakon što identificirate ispravno ime paketa za instalaciju, zamijenite niz "tesseract-ocr-hin" s njim u prvoj gore navedenoj naredbi.
Korištenje Tesseract OCR za izdvajanje teksta iz slika
Uzmimo primjer slike prikazane u nastavku (preuzeto sa stranice Wikipedije za Linux):

Da biste izvukli tekst iz gornje slike, morate pokrenuti naredbu u sljedećem formatu:
$ tesseract snimanje.png izlaz -l engPokretanje gornje naredbe daje sljedeći izlaz:
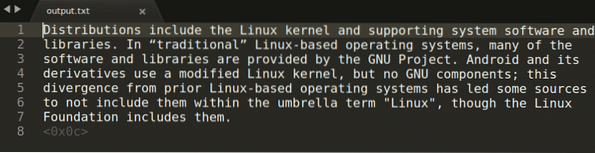
U gornjoj naredbi, „hvatanje.png ”odnosi se na sliku iz koje želite izvući tekst. Snimljeni izlaz se zatim pohranjuje u „izlaz.txt ”datoteku. Jezik možete promijeniti zamjenom argumenta "eng" vlastitim odabirom. Da biste vidjeli sve važeće jezike, pokrenite naredbu u nastavku:
$ tesseract --list-langsPokazat će se skraćenice za sve jezike koje u vašem sustavu podržava Tesseract OCR. Prema zadanim postavkama prikazat će samo "eng" kao izlaz. Međutim, ako instalirate pakete za dodatne jezike kako je gore objašnjeno, ova će naredba navesti više jezika koje možete koristiti za otkrivanje teksta (kao ISO 639 troslovni kodovi jezika).
Ako slika sadrži tekst na više jezika, definirajte prvo primarni jezik, a zatim dodatne jezike odvojene znakovima plus.
$ tesseract snimanje.png izlaz -l eng + fraAko želite pohraniti izlaz kao PDF datoteku koja se može pretraživati, pokrenite naredbu u sljedećem formatu:
$ tesseract snimanje.png izlaz -l eng pdfImajte na umu da PDF datoteka koju je moguće pretraživati neće sadržavati tekst koji se može uređivati. Uključuje izvornu sliku, s dodatnim slojem koji sadrži prepoznati tekst koji je postavljen na sliku. Dakle, iako ćete moći precizno pretraživati tekst u PDF datoteci pomoću bilo kojeg PDF čitača, nećete moći uređivati tekst.
Još jedna stvar koju biste trebali primijetiti da se točnost otkrivanja teksta uvelike povećava ako je slikovna datoteka visoke kvalitete. Ako imate mogućnost izbora, uvijek koristite formate datoteka bez gubitaka ili PNG datoteke. Korištenje JPG datoteka možda neće dati najbolje rezultate.
Izdvajanje teksta iz PDF datoteke s više stranica
Tesseract OCR izvorno ne podržava izdvajanje teksta iz PDF datoteka. Međutim, moguće je izvući tekst iz PDF datoteke s više stranica pretvaranjem svake stranice u datoteku slike. Pokrenite naredbu u nastavku za pretvorbu PDF datoteke u skup slika:
$ pdftoppm -png datoteka.pdf izlazZa svaku stranicu PDF datoteke dobit ćete odgovarajući "output-1.png "," izlaz-2.png ”datoteku i tako dalje.
Sada, da biste izdvojili tekst iz ovih slika pomoću jedne naredbe, morat ćete upotrijebiti petlju "for" u bash naredbi:
$ za i u *.png; napraviti tesseract "$ i" "output- $ i" -l eng; gotovo;Pokretanjem gornje naredbe izvući će se tekst iz svih “.png ”datoteke pronađene u radnom direktoriju i pohranjuju prepoznati tekst u“ output-original_filename.txt ”datoteke. Možete izmijeniti srednji dio naredbe prema vašim potrebama.
Ako želite kombinirati sve tekstualne datoteke koje sadrže prepoznati tekst, pokrenite naredbu u nastavku:
$ mačka *.txt> pridružio.txtProces izdvajanja teksta iz PDF datoteke s više stranica u PDF datoteke koje je moguće pretraživati gotovo je jednak. Naredbi morate dostaviti dodatni argument „pdf“:
$ za i u *.png; napraviti tesseract "$ i" "output- $ i" -l eng pdf; gotovo;Ako želite kombinirati sve PDF datoteke koje mogu pretraživati i sadrže prepoznatljiv tekst, pokrenite naredbu u nastavku:
$ pdfunite *.pdf pridružio.pdfI „pdftoppm“ i „pdfunite“ su prema zadanim postavkama instalirani na najnoviju stabilnu verziju Ubuntua.
Prednosti i nedostaci izdvajanja teksta u TXT i pretražive PDF datoteke
Ako izvučete prepoznati tekst u TXT datoteke, dobit ćete izlaz za tekst koji se može uređivati. Međutim, izgubit će se svako oblikovanje dokumenta (podebljano, kurziv i tako dalje). PDF datoteke koje se mogu pretraživati sačuvat će izvorno oblikovanje, ali izgubit ćete mogućnosti uređivanja teksta (još uvijek možete kopirati sirovi tekst). Ako otvorite PDF datoteku koju možete pretraživati u bilo kojem PDF uređivaču, dobit ćete ugrađene slike u datoteku, a ne izlaz sirovog teksta. Pretvaranjem PDF datoteka koje je moguće pretraživati u HTML ili EPUB dobit ćete i ugrađene slike.
Zaključak
Tesseract OCR jedan je od najčešće korištenih OCR motora danas. To je besplatan, otvoreni izvor i podržava više od stotinu jezika. Kada upotrebljavate Tesseract OCR, pobrinite se da koristite slike visoke rezolucije i ispravite jezične kodove u argumentima naredbenog retka kako biste poboljšali točnost otkrivanja teksta.