Python sadrži modul s imenom urllib za rukovanje zadacima povezanim s jedinstvenim lokatorom resursa (URL). Ovaj je modul po defaultu instaliran u Python 3 i dohvaća URL-ove različitih protokola putem urlopen () funkcija. Urllib se može koristiti u mnoge svrhe, poput čitanja sadržaja web mjesta, izrade HTTP i HTTPS zahtjeva, slanja zaglavlja zahtjeva i dohvaćanja zaglavlja odgovora. The urllib modul sadrži mnoge druge module za rad s URL-ovima, poput urllib.zahtjev, urllib.raščlaniti, i urllib.pogreška, između ostalih. Ovaj vodič će vam pokazati kako koristiti modul Urllib u Pythonu.
Primjer 1: Otvaranje i čitanje URL-ova pomoću urlliba.zahtjev
The urllib.zahtjev modul sadrži klase i metode potrebne za otvaranje i čitanje bilo kojeg URL-a. Sljedeća skripta pokazuje kako se koristi urllib.zahtjev modul za otvaranje URL-a i čitanje sadržaja URL-a. Evo, urlopen () metoda se koristi za otvaranje URL-a, “https: // www.linuxhint.com /.”Ako je URL važeći, tada će se sadržaj URL-a pohraniti u imenovanu varijablu objekta odgovor. The čitati() metoda odgovor objekt se zatim koristi za čitanje sadržaja URL-a.
#!/ usr / bin / env python3# Modul zahtjeva za uvoz urlliba
uvoz urllib.zahtjev
# Otvorite određeni URL za čitanje pomoću urlopen ()
odgovor = urllib.zahtjev.urlopen ('https: // www.linuxhint.com / ')
# Ispišite podatke o odgovoru URL-a
print ("Izlaz URL-a je: \ n \ n", odgovor.čitati())
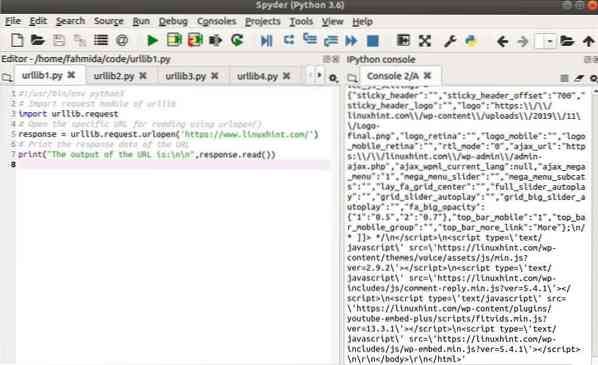
Izlaz
Sljedeći će se izlaz pojaviti nakon pokretanja skripte.
Primjer 2: Raščlanjivanje i uklanjanje URL-ova pomoću urllib-a.raščlaniti
The urllib.raščlaniti modul se prvenstveno koristi za razdvajanje ili spajanje različitih komponenata URL-a. Sljedeća skripta prikazuje različite namjene urllib.raščlaniti modul. Četiri funkcije urllib.raščlaniti koristi se u sljedećoj skripti uključuju urlparse, urlunparse, urlsplit, i urlunsplit. The urlparse modul radi kao urlsplit, i urlunparse modul radi kao urlunsplit. Između ovih funkcija postoji samo jedna razlika; to je, urlparse i urlunparse sadrže dodatni parametar pod nazivom 'parametarima'za razdvajanje i funkciju spajanja. Ovdje je URL 'https: // linuxhint.com / play_sound_python / 'koristi se za razdvajanje i pridruživanje URL-a.
#!/ usr / bin / env python3# Uvoz modula za raščlanjivanje urlliba
uvoz urllib.raščlaniti
# Analiziranje URL-a pomoću urlparse ()
urlParse = urllib.raščlaniti.urlparse ('https: // linuxhint.com / play_sound_python / ')
print ("\ nIzlaz URL-a nakon raščlanjivanja: \ n", urlParse)
# Spajanje URL-a pomoću urlunparse ()
urlUnparse = urllib.raščlaniti.urlunparse (urlParse)
print ("\ nUdruženi izlaz za raščlanjivanje URL-a: \ n", urlUnparse)
# Analiziranje URL-a pomoću urlsplit ()
urlSplit = urllib.raščlaniti.urlsplit ('https: // linuxhint.com / play_sound_python / ')
print ("\ nIzlaz URL-a nakon razdvajanja: \ n", urlSplit)
# Spajanje URL-a pomoću urlunsplit-a ()
urlUnsplit = urllib.raščlaniti.urlunsplit (urlSplit)
print ("\ nUdruženi izlaz dijeljenja URL-a: \ n", urlUnsplit)
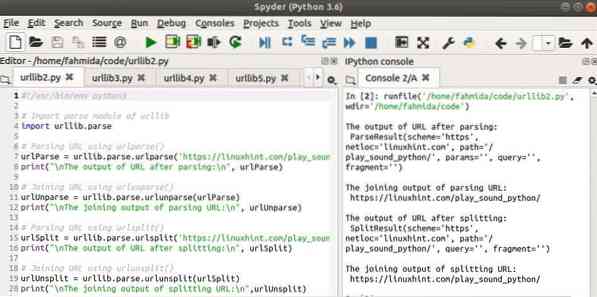
Izlaz
Sljedeća četiri izlaza pojavit će se nakon pokretanja skripte.
Primjer 3: Čitanje zaglavlja odgovora HTML-a s urllibom.zahtjev
Sljedeća skripta pokazuje kako se različiti dijelovi zaglavlja odgovora URL-a mogu pronaći putem informacije () metoda. The urllib.zahtjev modul koji se koristi za otvaranje URL-a, 'https: // linuxhint.com / python_pause_user_input /,'i podaci zaglavlja ovog URL-a ispisuju se putem informacije () metoda. Sljedeći dio ove skripte pokazat će vam kako zasebno čitati svaki dio zaglavlja. Evo, Poslužitelj, Datum, i Vrsta sadržaja vrijednosti se ispisuju zasebno.
#!/ usr / bin / env python3# Modul zahtjeva za uvoz urlliba
uvoz urllib.zahtjev
# Otvorite URL za čitanje
urlResponse = urllib.zahtjev.urlopen ('https: // linuxhint.com / python_pause_user_input / ')
# Čitanje izlaza zaglavlja odgovora URL-a
ispis (urlResponse.info ())
# Odvojeno čitanje podataka zaglavlja
ispis ('Response server =', urlResponse.info () ["Poslužitelj"])
print ('Datum odgovora je =', urlResponse.info () ["Datum"])
print ('Vrsta sadržaja odgovora je =', urlResponse.info () ["Vrsta sadržaja"])
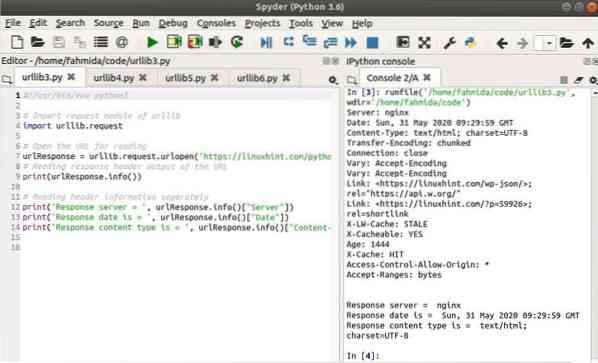
Izlaz
Sljedeći će se izlaz pojaviti nakon pokretanja skripte.
Primjer 4: Čitanje URL odgovora redak po redak
Lokalna URL adresa koristi se u sljedećoj skripti. Ovdje je nazvana ispitna HTML datoteka test.html kreira se na lokaciji, var /www / html. Sadržaj ove datoteke čita se redak po redak putem za petlja. The traka() Tada se metoda koristi za uklanjanje prostora s obje strane svake crte. Za testiranje skripte možete koristiti bilo koju HTML datoteku s lokalnog poslužitelja. Sadržaj test.html Datoteka koja se koristi u ovom primjeru data je u nastavku.
test.html:
Stranica za testiranje
#!/ usr / bin / env python3
# Uvezi urllib.modul zahtjeva
uvoz urllib.zahtjev
# Otvorite lokalni url za čitanje
odgovor = urllib.zahtjev.urlopen ('http: // localhost / test.html ')
# Pročitajte URL iz odgovora
print ('URL:', odgovor.geturl ())
# Pročitajte tekst odgovora redak po redak
print ("\ nČitanje sadržaja:")
za liniju kao odgovor:
ispis (redak.traka())
Izlaz
Sljedeći će se izlaz pojaviti nakon pokretanja skripte.

Primjer 5: Rukovanje iznimkom s urllibom.pogreška.URLEpogreška
Sljedeća skripta pokazuje kako se koristi URLEpogreška u Pythonu putem urllib.pogreška modul. Bilo koja URL adresa može se uzeti kao ulaz od korisnika. Ako adresa ne postoji, tada se pojavljuje znak URLEpogreška Pojavit će se iznimka i ispisat će se razlog pogreške. Ako je vrijednost URL-a u nevaljanom formatu, tada Pogreška vrijednosti bit će pokrenut i ispisat će se prilagođena pogreška.
#!/ usr / bin / env python3# Uvezite potrebne module
uvoz urllib.zahtjev
uvoz urllib.pogreška
# pokušajte blokirati da biste otvorili bilo koji URL za čitanje
probati:
url = input ("Unesite bilo koju URL adresu:")
odgovor = urllib.zahtjev.urlopen (url)
ispis (odgovor.čitati())
# Uhvatite pogrešku URL-a koja će se generirati prilikom otvaranja bilo kojeg URL-a
osim urlliba.pogreška.URLError kao e:
print ("Pogreška URL-a:", npr.razlog)
# Uhvatite neispravnu pogrešku URL-a
osim ValueError:
ispis ("Unesite važeću URL adresu")
Izlaz
Skripta se izvršava tri puta na sljedećem snimku zaslona. U prvoj je iteraciji URL adresa dana u nevaljanom formatu, generirajući ValueError. URL adresa navedena u drugoj iteraciji ne postoji, generirajući URLError. U trećoj je iteraciji navedena valjana URL adresa, pa se tako ispisuje sadržaj URL-a.

Primjer 6: Rukovanje iznimkom s urllibom.pogreška.HTTPError
Sljedeća skripta pokazuje kako se koristi HTTPError u Pythonu putem urllib.pogreška modul. An HTMLError generira kada navedena URL adresa ne postoji.
#!/ usr / bin / env python3# Uvezite potrebne module
uvoz urllib.zahtjev
uvoz urllib.pogreška
# Unesite bilo koji valjani URL
url = input ("Unesite bilo koju URL adresu:")
# Pošaljite zahtjev za URL
zahtjev = urllib.zahtjev.Zahtjev (url)
probati:
# Pokušajte otvoriti URL
urllib.zahtjev.urlopen (zahtjev)
ispis ("URL postoji")
osim urlliba.pogreška.HTTPError kao e:
# Ispišite kôd pogreške i razlog pogreške
print ("Kôd pogreške:% d \ nRazlog pogreške:% s"% (e.kod, npr.razlog))
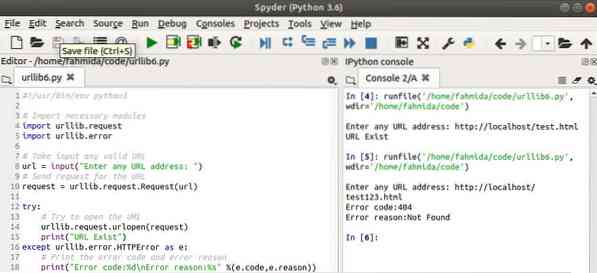
Izlaz
Ovdje se skripta izvršava dva puta. Prva URL adresa uzeta kao ulaz postoji i modul je ispisao poruku. Druga URL adresa uzeta kao ulaz ne postoji i modul je generirao HTTPError.
Zaključak
Ovaj je vodič raspravljao o mnogim važnim namjenama urllib modul pomoću različitih primjera kako bi čitateljima pomogao da znaju funkcije ovog modula u Pythonu.


