U ovom ćemo članku proći kroz osnovne uporabe grupe prema funkcijama u pandinom pythonu. Sve se naredbe izvršavaju na uređivaču Pycharm.
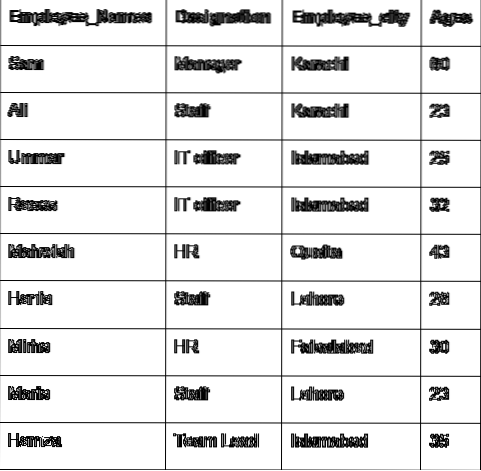
Razmotrimo glavni koncept grupe uz pomoć podataka zaposlenika. Izradili smo podatkovni okvir s nekim korisnim detaljima zaposlenika (Employee_Names, Oznaka, Employee_city, Age).
Spajanje nizova pomoću grupe po funkciji
Pomoću funkcije groupby možete povezati nizove. Isti se zapisi mogu spojiti s ',' u jednoj ćeliji.
Primjer
U sljedećem primjeru sortirali smo podatke na temelju stupca 'Oznaka zaposlenika' i pridružili se zaposlenicima koji imaju istu oznaku. Lambda funkcija primjenjuje se na "Employees_Name".
uvoziti pande kao pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
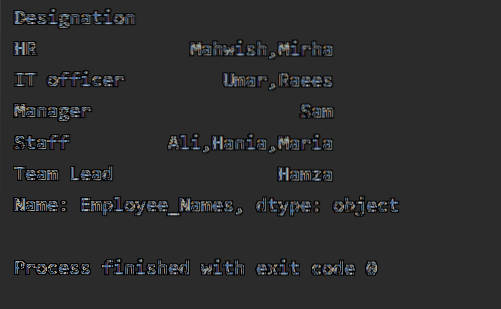
df1 = df.groupby ("Oznaka") ['Employee_Names'].primijeniti (lambda Employee_Names: ','.pridružiti se (Employee_Names))
ispis (df1)
Kada se izvrši gornji kod, prikazuje se sljedeći izlaz:
Sortiranje vrijednosti u rastućem redoslijedu
Upotrijebite objekt groupby u redoviti okvir podataka pozivanjem '.to_frame () ', a zatim koristite reset_index () za ponovni indeks. Razvrstavanje vrijednosti stupaca pozivanjem sort_values ().
Primjer
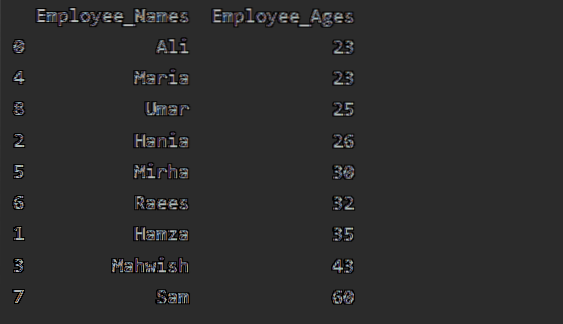
U ovom ćemo primjeru sortirati dob zaposlenika prema rastućem redoslijedu. Koristeći sljedeći dio koda, dohvatili smo 'Employee_Age' u rastućem redoslijedu s 'Employee_Names'.
uvoziti pande kao pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].iznos().Uokviriti().reset_index ().razvrstaj_vrijednosti (po = 'Dob zaposlenika')
ispis (df1)
Korištenje agregata s groupby
Dostupne su brojne funkcije ili agregacije koje možete primijeniti na podatkovne skupine kao što su count (), sum (), mean (), mediana (), mode (), std (), min (), max ().
Primjer
U ovom smo primjeru koristili funkciju 'count ()' s groupby za brojanje zaposlenika koji pripadaju istom 'Employee_city'.
uvoziti pande kao pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
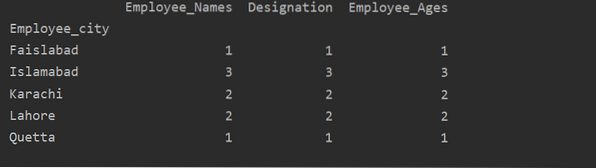
df1 = df.groupby ('Employee_city').računati()
ispis (df1)
Kao što možete vidjeti sljedeći izlaz, u stupce Oznaka, Imena zaposlenika i Zaposlenik_Starost prebrojte brojeve koji pripadaju istom gradu:
Vizualizirajte podatke pomoću groupby
Korištenjem 'import matplotlib.pyplot ', svoje podatke možete vizualizirati u grafikone.
Primjer
Ovdje slijedeći primjer vizualizira 'Employee_Age' s 'Employee_Nmaes' iz datog DataFrame-a pomoću naredbe groupby.
uvoziti pande kao pduvoz matplotlib.pyplot kao plt
okvir podataka = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
podatkovni okvir.groupby ('Employee_Names').iznos().zaplet (vrsta = 'traka')
plt.pokazati()
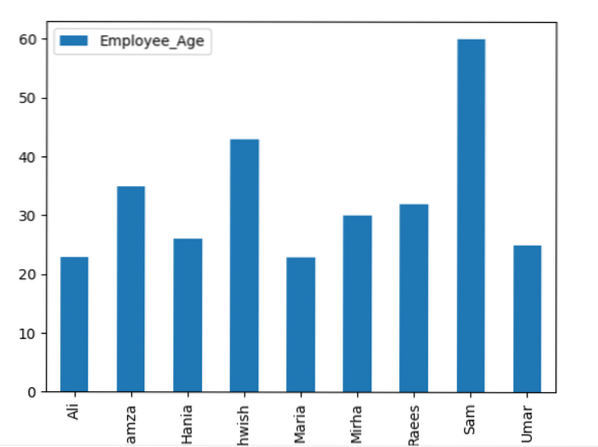
Primjer
Da biste nacrtali naslagani graf pomoću groupby, okrenite 'stacked = true' i upotrijebite sljedeći kod:
uvoziti pande kao pduvoz matplotlib.pyplot kao plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Employee_city', 'Employee_Names']).veličina().raspakirati ().zaplet (vrsta = 'bar', naslagan = True, fontsize = '6')
plt.pokazati()
Na donjem grafikonu prikazan je broj zaposlenih koji pripadaju istom gradu.
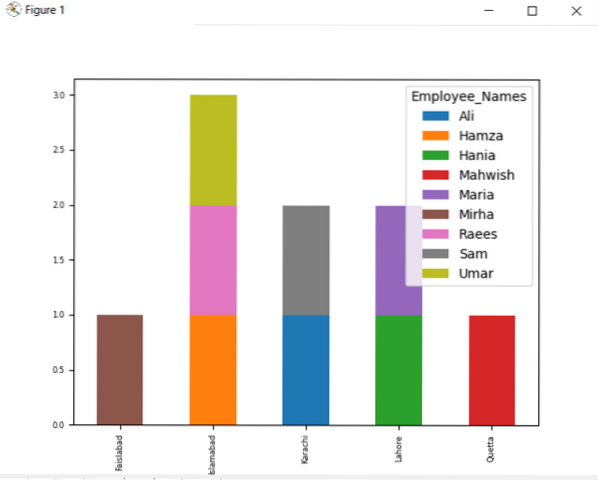
Promijenite naziv stupca s grupom do
Također možete promijeniti agregirani naziv stupca s nekim novim izmijenjenim imenom, kako slijedi:
uvoziti pande kao pduvoz matplotlib.pyplot kao plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Oznaka'].iznos().reset_index (name = 'Naziv_zaposlenika')
ispis (df1)
U gornjem primjeru, naziv "Oznaka" mijenja se u "Employee_Designation".
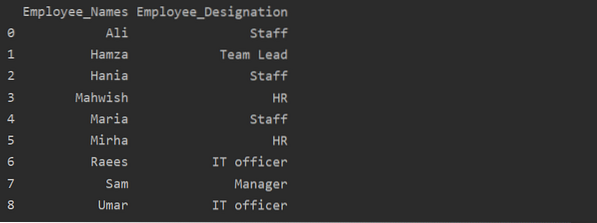
Dohvaćanje grupe prema ključu ili vrijednosti
Pomoću naredbe groupby možete dohvatiti slične zapise ili vrijednosti iz okvira podataka.
Primjer
U dolje navedenom primjeru imamo podatke o skupinama na temelju 'Oznake'. Zatim se pomoću "." Pronalazi grupa "Osoblje" .getgroup ('Osoblje').
uvoziti pande kao pduvoz matplotlib.pyplot kao plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
ekstrakt_vrijednost = df.groupby ('Oznaka')
ispis (extract_value.get_group ('Osoblje'))
Sljedeći rezultat prikazuje se u izlaznom prozoru:

Dodajte vrijednost na popis grupa
Slični podaci mogu se prikazati u obliku popisa pomoću naredbe groupby. Prvo grupirajte podatke na temelju stanja. Zatim, primjenom funkcije, ovu skupinu možete lako staviti na popise.
Primjer
U ovom smo primjeru uvrstili slične zapise na popis grupa. Svi su zaposlenici podijeljeni u grupu na temelju 'Employee_city', a zatim se primjenom funkcije 'Lambda' ova grupa preuzima u obliku popisa.
uvoziti pande kao pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].primijeniti (lambda group_series: group_series.izlistati()).reset_index ()
ispis (df1)
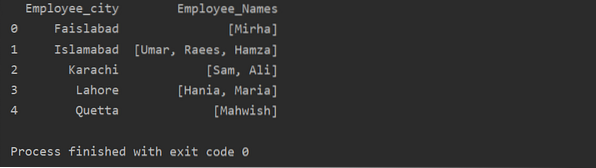
Korištenje funkcije Transform s groupby
Zaposlenici su grupirani prema dobi, te se vrijednosti zbrajaju, a pomoću funkcije 'transformiraj' u tablicu se dodaje novi stupac:
uvoziti pande kao pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Oznaka': ['Voditelj', 'Osoblje', 'IT službenik', 'IT službenik', 'HR', 'Osoblje', 'HR', 'Osoblje', 'Voditelj tima'],
'Grad zaposlenika': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Dob zaposlenika': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
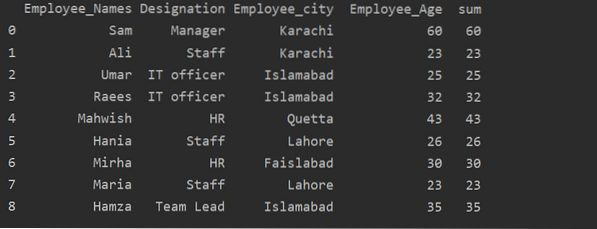
df ['zbroj'] = df.groupby (['Employee_Names']) ['Employee_Age'].pretvoriti ('zbroj')
ispis (df)
Zaključak
U ovom smo članku istražili različite upotrebe izjave groupby. Pokazali smo kako podatke možete podijeliti u grupe, a primjenom različitih agregacija ili funkcija možete lako doći do tih grupa.


