Ovaj vam članak pokazuje kako pronaći duplikate u podacima i ukloniti duplikate pomoću funkcija Pandas Python.
U ovom smo članku uzeli skup podataka stanovništva različitih država u Sjedinjenim Državama, koji je dostupan u .csv format datoteke. Čitat ćemo .csv datoteku za prikaz izvornog sadržaja ove datoteke, kako slijedi:
uvoziti pande kao pddf_state = pd.read_csv ("C: / Korisnici / DELL / Desktop / populacija_ds.csv ")
ispis (df_state)
Na sljedećem snimku zaslona možete vidjeti duplicirani sadržaj ove datoteke:
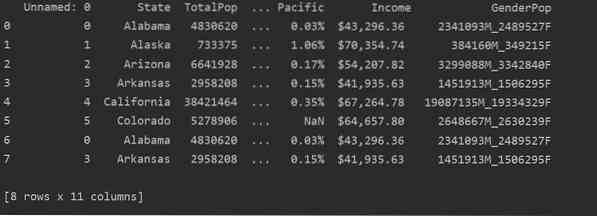
Prepoznavanje duplikata u Pandas Pythonu
Potrebno je utvrditi imaju li podaci koje upotrebljavate duplicirane retke. Da biste provjerili dupliciranje podataka, možete upotrijebiti bilo koji od načina obrađenih u sljedećim odjeljcima.
Metoda 1:
Pročitajte csv datoteku i prenesite je u okvir podataka. Zatim identificirajte duplicirane retke pomoću duplicirano () funkcija. Na kraju, upotrijebite iskaz za ispis da biste prikazali dvostruke retke.
uvoziti pande kao pddf_state = pd.read_csv ("C: / Korisnici / DELL / Desktop / populacija_ds.csv ")
Dup_Rows = df_state [df_state.duplicirano ()]
print ("\ n \ nDvostruki redovi: \ n ".format (Dup_Rows))
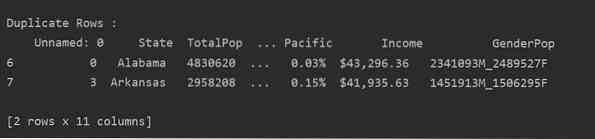
Metoda 2:
Koristeći ovu metodu, je_dvostručen stupac će se dodati na kraj tablice i označiti kao "True" u slučaju dupliciranih redaka.
uvoziti pande kao pddf_state = pd.read_csv ("C: / Korisnici / DELL / Desktop / populacija_ds.csv ")
df_state ["is_duplicate"] = df_state.duplicirano ()
ispis ("\ n ".format (df_state))
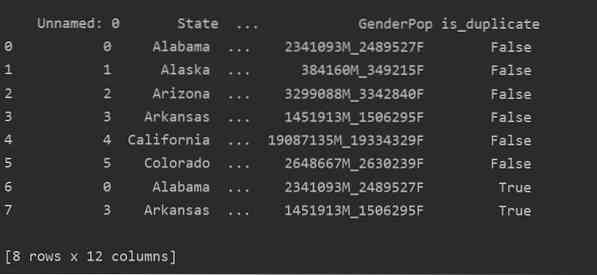
Ispuštanje duplikata u Pandas Python
Duplicirani retci mogu se ukloniti iz vašeg podatkovnog okvira pomoću sljedeće sintakse:
drop_duplicates (subset = ", keep =", inplace = False)
Gore navedena tri parametra nisu obavezna i detaljnije su objašnjena u nastavku:
zadržati: ovaj parametar ima tri različite vrijednosti: First, Last i False. Prva vrijednost zadržava prvu pojavu i uklanja naknadne duplikate, zadnja vrijednost zadržava samo posljednju pojavu i uklanja sve prethodne duplikate, a vrijednost False uklanja sve duplicirane retke.
podskup: oznaka koja se koristi za identificiranje dupliciranih redova
na mjestu: sadrži dva uvjeta: True i False. Ovaj će parametar ukloniti duplicirane retke ako je postavljen na True.
Uklonite duplikate zadržavajući samo prvu pojavu
Kada koristite "keep = first", zadržat će se samo pojavljivanje prvog retka, a svi ostali duplikati uklonit će se.
Primjer
U ovom će se primjeru zadržati samo prvi redak, a preostali će se duplikati izbrisati:
uvoziti pande kao pddf_state = pd.read_csv ("C: / Korisnici / DELL / Desktop / populacija_ds.csv ")
Dup_Rows = df_state [df_state.duplicirano ()]
print ("\ n \ nDvostruki redovi: \ n ".format (Dup_Rows))
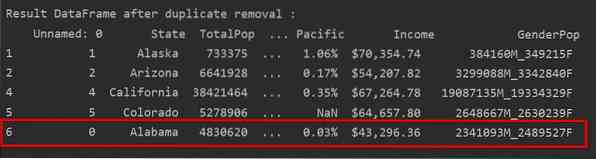
DF_RM_DUP = df_state.drop_duplicates (keep = 'first')
print ('\ n \ nRezultat podatkovnog okvira nakon uklanjanja duplikata: \ n', DF_RM_DUP.glava (n = 5))
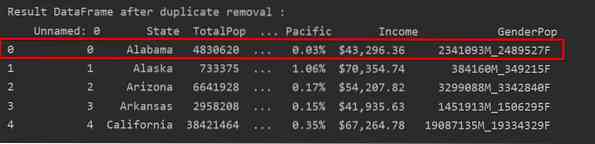
Na sljedećem snimku zaslona zadržani događaj prvog retka označen je crvenom bojom, a preostale duplikate uklonjene su:
Uklonite duplikate zadržavajući samo posljednju pojavu
Kada koristite "keep = last", uklonit će se svi duplicirani retci, osim posljednjeg pojavljivanja.
Primjer
U sljedećem primjeru uklanjaju se svi duplicirani retci, osim samo posljednjeg pojavljivanja.
uvoziti pande kao pddf_state = pd.read_csv ("C: / Korisnici / DELL / Desktop / populacija_ds.csv ")
Dup_Rows = df_state [df_state.duplicirano ()]
print ("\ n \ nDvostruki redovi: \ n ".format (Dup_Rows))
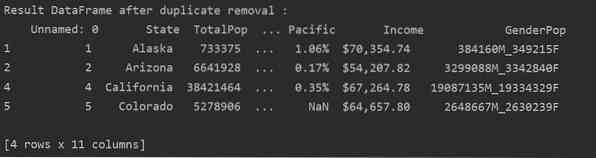
DF_RM_DUP = df_state.drop_duplicates (keep = 'last')
print ('\ n \ nRezultat okvira podataka nakon uklanjanja duplikata: \ n', DF_RM_DUP.glava (n = 5))
Na sljedećoj su slici duplikati uklonjeni i zadržava se samo posljednji redak:
Ukloni sve duplikate redaka
Da biste uklonili sve dvostruke retke iz tablice, postavite "keep = False" kako slijedi:
uvoziti pande kao pddf_state = pd.read_csv ("C: / Korisnici / DELL / Desktop / populacija_ds.csv ")
Dup_Rows = df_state [df_state.duplicirano ()]
print ("\ n \ nDvostruki redovi: \ n ".format (Dup_Rows))
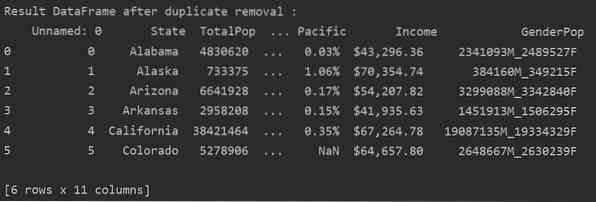
DF_RM_DUP = df_state.drop_duplicates (keep = False)
print ('\ n \ nRezultat okvira podataka nakon uklanjanja duplikata: \ n', DF_RM_DUP.glava (n = 5))
Kao što možete vidjeti na sljedećoj slici, svi se duplikati uklanjaju iz okvira podataka:
Uklonite povezane duplikate iz određenog stupca
Prema zadanim postavkama, funkcija provjerava sve duplicirane retke iz svih stupaca u danom podatkovnom okviru. Ali, naziv stupca možete odrediti i pomoću parametra podskupa.
Primjer
U sljedećem primjeru svi povezani duplikati uklanjaju se iz stupca 'Države'.
uvoziti pande kao pddf_state = pd.read_csv ("C: / Korisnici / DELL / Desktop / populacija_ds.csv ")
Dup_Rows = df_state [df_state.duplicirano ()]
print ("\ n \ nDvostruki redovi: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (subset = 'State')
print ('\ n \ nRezultat okvira podataka nakon uklanjanja duplikata: \ n', DF_RM_DUP.glava (n = 6))
Zaključak
Ovaj vam je članak pokazao kako ukloniti duplicirane retke iz okvira podataka pomoću drop_duplicates () funkcija u Pandas Pythonu. Pomoću ove funkcije također možete očistiti podatke od umnožavanja ili suvišnosti. Članak vam je također pokazao kako prepoznati sve duplikate u vašem podatkovnom okviru.


