Funkcija grepa je pretražiti tekst i primijeniti uvjete na njih. Koristi se za pretraživanje u više datoteka. Grep može prepoznati retke teksta u njemu i odlučiti dalje primijeniti različite radnje koje uključuju rekurzivnu funkciju ili inverzno pretraživanje i prikazuju broj retka kao izlaz itd. Posebni znakovi su regularni izrazi koji se koriste u naredbama za izvršavanje nekoliko radnji poput #,%, *, &, $, @, itd. U ovom ćemo članku koristiti posebne znakove. Grep dopušta argumente kao nizove koji su navedeni kao regularni izraz. Također ima mogućnost zamjene riječi ili izraza u njemu. Posebni se znakovi ne koriste samo kao naziv datoteke već i kao podaci prisutni u datoteci.
Preduvjet
Da bismo je izvršili, moramo imati operativni sustav Linux. Da bi se Linux mogao pokrenuti, moramo imati unaprijed instaliran virtualni okvir. Nakon uspješne instalacije Linuxa, konfigurirat ćete ga davanjem nekih korisnih informacija. Sljedeći je korak ulazak na početnu stranicu Ubuntu Linuxa. Davanjem korisničkog imena i lozinke moći ćete pristupiti svim aplikacijama -typectrl + alt + t za otvaranje terminala.
Upotreba "$"
Da biste razumjeli koncept posebnog znaka "$" u naredbi grep, morate imati datoteku koja se zove datoteka21.txt. "$" Se koristi za prikaz svih redaka koji imaju znak definiran iza "$", što je točka i zarez, tj.e., '; $'. Sav relevantan sadržaj možemo prikazati pomoću naredbe cat.
$ Cat datoteka21.txt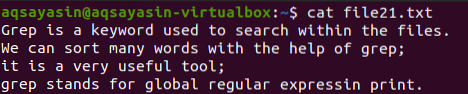
Sada ćemo upotrijebiti znak u sljedećoj naredbi da bismo razumjeli kako to radi. "-E" pomaže prikazati točno podudaranje u datoteci.
$ grep -e '; $' datoteka21.txt
Gornji izlaz prikazuje sve retke u datoteci s zarezom „;“ na kraju. Odgovarajući rezultat istaknut je uz svaki redak.
Korištenje "
Ovo je jednostavan primjer regularnog izraza. U bilo kojoj grep izjavi, pojedinačni navodnici koriste se kada želimo podudarati bilo koju riječ unutar datoteke. Slično tome, spomenuli smo ovaj primjer kako bismo ga učinili preciznim i razumljivim za korisnika.
$ grep -e datoteka 'Aqsa '23.txtIzlaz će sadržavati sve rečenice koje sadrže riječ Aqsa u sebi jer smo ovu riječ pretraživali u naredbi.

Korištenje []
Uglate zagrade koriste se za spominjanje riječi koju treba pretražiti između dva para uglastih zagrada. Ove uglate zagrade slijede "*" u naredbi. Štoviše, u naredbi smo koristili -n -I -w -e da bismo točno dobili izlaz s brojem retka, zanemarujući osjetljivost na mala i velika slova i dobili točno podudaranje koje se dogodilo više puta u datoteci. Koristit ćemo datoteku fileg.txt za prikaz podataka koji se u njemu nalaze. -E se koristi kao prošireni regularni izraz kad god koristimo bilo koji znak u naredbi.
$ Cat datotekag.txt
Sada ćemo primijeniti sljedeći upit.
$ grep -noiwe -e '[] * datoteka [] *'.txt
Gdje fileg.txt je dotična datoteka. Izlaz prikazuje riječ "the" gdje god je prisutna u datoteci, zajedno s brojem retka. Prikazuje se samo riječ, ali ne i cijela rečenica, jer smo koristili -w i -e da prikažemo njezinu pojavu i pokažemo točnost.
Korištenje "-"
'-' koristi se u naredbi za pronalaženje podudaranja u datoteci. -niw opet predstavlja isto značenje kao što je opisano u gore spomenutom primjeru. -m prikazuje prvi redak koji sadrži riječ u postojećoj datoteci.
$ grep -niw -m 3 'tehnička' datoteka1.txt
Izlaz prikazuje retke koji sadrže riječ tehnički. Prikazuje se i broj retka koji ima riječ "tehnički", a nalazi se u 1 i 4.
Korištenje "|"
Ovaj se posebni znak koristi na mnogo načina. Općenito, koristi se kao operator ILI za odabir između dva dana imena. U naredbi grep koristi se za rad tako da će dohvatiti zapis jedne ili obje riječi odvojene znakom "|". Ovdje primjer pokazuje dohvaćanje dviju riječi prisutnih u svim datotekama direktorija.
$ grep -I -E -w 'Aqsa | dobro' / home / aqsayasin / datoteka *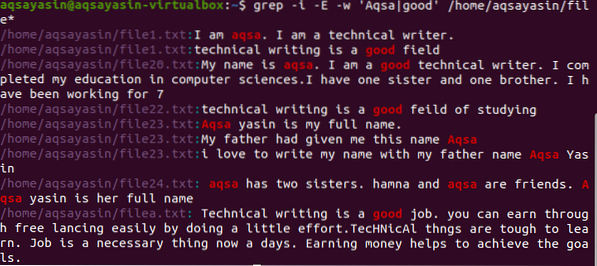
Sada izlaz prikazuje obje riječi prisutne u jednoj datoteci ili u različitim datotekama. Kao što smo spomenuli u direktoriju, dobit ćemo i imena datoteka.
Korištenje '^ ()'
Ovdje '^ ()' djeluje rekurzivno u usporedbi s gornjim primjerom."^" Prikazuje samo jednu od dvije zadane mogućnosti, tj.e., Aqsa i dobro, to je prvo u bilo kojoj datoteci. Izlaz će sadržavati samo Aqsu. Egrep je prošireni regularni izraz.
$ egrep -I '^ (aqsa | dobro)' / home / aqsayasin / *.txt
Koristeći ^ $
Prikazuje podudaranje praznih / praznih nizova na kraju retka. Ako je unutar teksta prisutna praznina, ona se dohvaća sljedećom naredbom.
$ grep -n '^ $' / home / aqsayasin / *.txt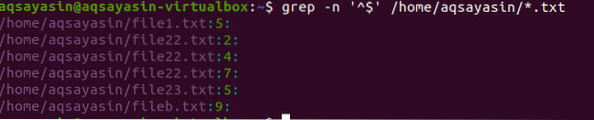
Pretražit će se sve tekstualne datoteke. Izlaz će sadržavati imena datoteka, kao i broj retka koji sadrži prazno mjesto u datoteci. U naredbi smo koristili -n.

Upotreba []
Ove dvije zagrade pokazuju kako rade posebni likovi. [] sadrži riječ koju treba pretražiti. Istovremeno, opišite podudaranje u datoteci N puta. U slijedećem primjeru koristili smo 2, koji pokazuje pojavu sve dvije moguće riječi navedene riječi u naredbi koja je "the".
$ egrep '[the] 2' / home / aqsayasin / datoteka *
Zaključak
U ranije spomenutom članku razgovarali smo o nekim osnovnim primjerima koji objašnjavaju pojam posebnih znakova u naredbi. Stvorili smo datoteku, a zatim dohvatili podatke koji su u njoj pomoću naredbe grep. Nadam se da ćete nakon čitanja ovog članka biti upoznati s posebnim znakovima koje smo koristili u našem članku.


