Sintaksa
Grep [uzorak] [naziv datoteke]
Nakon upotrebe grepa, dolazi obrazac. Uzorak podrazumijeva način na koji ga želimo koristiti u uklanjanju suvišnog prostora u podacima. Slijedeći uzorak, opisuje se naziv datoteke kroz koji se uzorak izvodi.
Preduvjet
Da bismo lako razumjeli korisnost grepa, na našem sustavu mora biti instaliran Ubuntu. Navedite korisničke detalje davanjem korisničkog imena i lozinke kako biste imali povlastice u pristupu aplikacijama Linuxa. Nakon prijave otvorite program i potražite terminal ili primijenite prečac tipke ctrl + alt + T.
Korištenjem ključne riječi [: blank:]
Pretpostavimo da imamo datoteku pod nazivom bfile koja ima tekstualnu ekstenziju. Datoteku možete stvoriti u uređivaču teksta ili pomoću naredbenog retka u terminalu. Za stvaranje datoteke na terminalu, uključujući sljedeće naredbe.
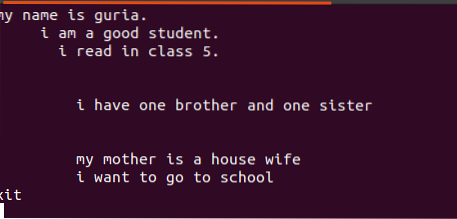
$ Echo “tekst koji se unosi u datoteku”> naziv datoteke.txtNema potrebe za izradom datoteke ako je već prisutna. Samo ga prikažite pomoću dodane naredbe:
$ echo naziv datoteke.txtTekst napisan u ovim datotekama sadrži razmake između njih, kao što se vidi na donjoj slici.
![]()
Ti se prazni redovi mogu ukloniti pomoću prazne naredbe za ignoriranje praznih razmaka između riječi ili nizova.
$ egrep '^ [[: blank]] * [^ [: blank:] #]' bfile.txt![]()
Nakon primjene upita, prazni razmaci između redaka uklonit će se, a izlaz više neće sadržavati dodatni prostor. Prva je riječ istaknuta jer se uklanjaju razmaci između posljednje riječi retka i između prvih riječi sljedećeg retka. Također možemo primijeniti uvjete na istu grep naredbu dodavanjem ove prazne funkcije za uklanjanje beskorisnog prostora u izlazu.
Korištenjem [: space:]
Ovdje je objašnjen još jedan primjer ignoriranja prostora.
Bez spominjanja ekstenzije datoteke, prvo ćemo prikazati postojeću datoteku pomoću naredbe.
$ mačka datoteka20![]()
Pogledajmo kako se uklanja dodatni prostor pomoću naredbe grep pored ključne riječi [: space:]. Grepova opcija -v pomoći će ispisu redaka kojima nedostaju prazni redovi i dodatni razmak koji je također uključen u obrazac odlomka.
$ grep -v '^ [[; razmak:]] * $' datoteka20Vidjet ćete da su dodatni retci uklonjeni i izlaz je u sekvenciranom obliku linijski. Tako je grep -v metodologija toliko korisna u postizanju traženog cilja.
![]()
Spominjanje ekstenzija datoteka ograničava grep funkciju da se izvodi samo na određenim ekstenzijama datoteka, tj.e., .tekst ili .mp3. Dok izvodimo poravnanje tekstualne datoteke, uzet ćemo fileg.txt kao ogledna datoteka. Prvo ćemo prikazati tekst koji je prisutan u njemu pomoću funkcije $ cat. Izlaz je sljedeći:
![]()
Primjenom naredbe dobivena je naša izlazna datoteka. Ovdje možemo vidjeti podatke bez razmaka između redaka koji su uzastopno napisani.
$ grep -v '^ [[: razmak:]] * $' datotekag.txt![]()
Osim dugih naredbi, možemo koristiti i kratke napisane naredbe u Linuxu i Unixu kako bismo u njih implementirali grep koji podržava skraćene znakove.
$ grep '\ s' naziv datoteke.txtVidjeli smo kako se izlaz dobiva primjenom naredbi s ulaza. Ovdje ćemo naučiti kako se ulaz održava natrag iz rezultata.
$ grep '\ S' naziv datoteke.txt> tmp.txt && mv tmp.txt naziv datoteke.txtOvdje ćemo koristiti privremenu tekstualnu datoteku s nastavkom teksta nazvanog tmp.
Korištenjem ^ #
Baš kao i drugi opisani primjeri, naredbu ćemo primijeniti na tekstualnu datoteku pomoću naredbe cat. Tekst možemo prikazati i pomoću naredbe echo.
$ echo naziv datoteke.txtTekstualna datoteka sadrži 4 retka s razmakom između njih. Te se razmaknice lako uklanjaju pomoću određene naredbe.
![]()
Redovne proširene operacije omogućuje -E, što omogućuje sve regularne izraze, posebno pipe. Cijev se koristi kao neobavezni uvjet "ili" u bilo kojem uzorku.”^ #”. To pokazuje podudaranje redaka teksta u datoteci koja započinje znakom #. “^ $” Će se podudarati sa svim slobodnim razmacima u tekstu ili praznim redovima.
![]()
Izlaz prikazuje potpuno uklanjanje suvišnog razmaka između linija prisutnih u podatkovnoj datoteci. U ovom primjeru vidjeli smo da je u naredbi "^ #" na prvom mjestu, što znači da se prvo podudara tekst. "^ $" Dolazi nakon | operatora, tako da se slobodni prostor usklađuje nakon toga.
Korištenjem ^ $
Baš kao i gore spomenuti primjer, doći ćemo s istim rezultatima jer je naredba gotovo ista. Međutim, obrazac je napisan suprotno. Datoteka22.txt je datoteka koju ćemo koristiti za uklanjanje razmaka.
![]()
Primjenjuje se ista metodologija, osim rada s prioritetom. Prema ovoj naredbi prvo će se podudarati slobodni prostori, a zatim se podudaraju tekstualne datoteke. Izlaz će pružiti slijed linija uklanjanjem dodatnih praznina u njima.
![]()
Ostale jednostavne naredbe
- Grep '^ ...' naziv datoteke.
- Grep '.' Naziv datoteke
Oboje su tako jednostavni i pomažu u uklanjanju praznina u retcima teksta.
Zaključak
Uklanjanje beskorisnih praznina u datotekama uz pomoć regularnih izraza prilično je jednostavan pristup za postizanje glatkog slijeda podataka i održavanje dosljednosti. Primjeri su detaljno objašnjeni kako bi se poboljšali vaši podaci o temi.


