Sintaksa
$ grep 'pattern1 \ | pattern2' naziv datotekeRegularni izraz uvijek je napisan u jednom navodniku. Dva su imena odvojena kosom crtom i operatorom izmjene. Naredba se završava imenom datoteke. Dok se grep vrši rekurzivno, umjesto jednog naziva datoteke koristi se direktorij ili cijela staza.
Preduvjet
U ovom ćemo članku naučiti funkcionalnost grepa u pretraživanju višestrukih uzoraka i nizova. U tu svrhu trebate imati Linux operativni sustav pokrenut na vašoj virtualnoj kutiji. Morate ga instalirati na svoj sustav. Nakon konfiguracije imat ćete pristup korištenju svih aplikacija. Nakon prijave na korisnika davanjem lozinke, idite na naredbenu liniju ljuske terminala da biste nastavili.
Pretraživanje po višestrukim uzorcima u datoteci pomoću grepa
Ako želimo pretraživati više uzoraka ili nizova u određenoj datoteci, upotrijebite funkciju grep za sortiranje unutar datoteke uz pomoć više od jedne ulazne riječi u naredbi. Koristimo '\ |' operatora za razdvajanje dva uzorka u naredbi.
$ grep 'tehnička \ | zadaća' datoteka.txtNaredba predstavlja kako grep radi. Obje spomenute datoteke pretražit će se u filea.txt. Tražene riječi istaknute su u cijelom tekstu rezultata.

Da bismo tražili više od dvije riječi, nastavit ćemo ih dodavati na isti način.
$ grep 'graphic \ | photoshop \ | posters' datotekab.txt
Pretražite više žica ignorirajući slučaj
Da biste razumjeli koncept osjetljivosti na velika i mala slova u funkciji grep u Linuxu, razmotrite sljedeći primjer. Dvije grende rade na grepu. Jedno je s '-i', a drugo je bez. Ovaj primjer pokazuje razlike između naredbi. Prva pokazuje da će se dvije riječi pretraživati u datoj datoteci. Međutim, kao što je naznačeno u naredbi "Aqsa", započinje velikim slovom A. Stoga neće biti istaknuto jer je u određenoj datoteci ovaj tekst malim slovima.
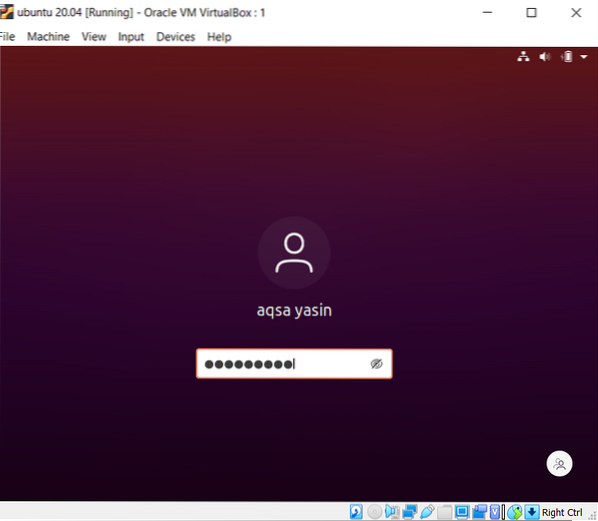
$ grep datoteka 'Aqsa \ | sestra '20.txtRazmatrat će samo riječ sestra, što će se vidjeti u izlazu.
U drugom primjeru zanemarili smo osjetljivost na mala i velika slova koristeći zastavicu "-I". Ova će funkcija pretraživati obje riječi, a izlaz će biti istaknut. Bez obzira na to je li riječ 'Aqsa' napisana velikim slovima ili ne, grep će tražiti isto podudaranje u tekstu unutar datoteke. Dakle, obje su naredbe korisne na svoj način.
$ grep -Datoteka 'Aqsa \ | sestra '20.txt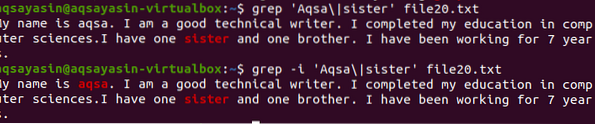
Brojanje više podudaranja u datoteci
Funkcija brojanja pomaže u brojanju pojavljivanja riječi ili riječi u određenoj datoteci. Na primjer, ako želite znati o pogreškama koje se događaju u sustavu. Pojedinosti su zabilježene u datoteci dnevnika. Da biste zadržali ove podatke u određenoj mapi, napisat ćete put mapa. Ovaj primjer pokazuje da se u datotekama dnevnika dogodila 71 pogreška.

Pretražite točna podudaranja u datoteci
Ako želite pronaći točno podudaranje u datotekama vašeg sustava, morate upotrijebiti zastavicu "-w" da biste ga točno sortirali. Naveli smo jednostavan i sveobuhvatan primjer. U primjeru ispod, razmislite o pretraživanju bez “-w”, ova naredba donijet će obje riječi kao da se podudaraju s danim unosom. No, upotrebom zastavice "-w", pretraživanje će biti ograničeno jer se ulazne riječi podudaraju samo s prvim nizom. Druga riječ nije istaknuta jer "-w" omogućuje točno podudaranje s uzorkom.
$ -iw 'hamna \ | kuća' datoteka21.txtOvdje -I se također koristi za uklanjanje osjetljivosti na velika i mala slova u pretraživanju teksta.

Kao što se vidi na fotografiji, rezultati nisu isti. Prva naredba donosi sve povezane podatke s cijelim nizovima, dok druga naredba pokazuje kako se točni podaci podudaraju kroz grep u traženju višestrukih nizova.
Grep za više uzoraka u određenoj vrsti ekstenzije datoteke
Pretraživanje se vrši unutar svih datoteka. Na vama je ako tražite davanjem imena datoteke. Tražit će samo u određenim datotekama. No pružanjem nastavka datoteke, podaci će se pretraživati kroz sve datoteke istog nastavka. Postoje dva različita primjera koji prikazuju povezani rezultat. Uzimajući u obzir prvi primjer, datoteke pogrešaka će se brojati u svim datotekama .nastavak dnevnika. "-C" se koristi za brojanje.
$ grep -c 'upozorenje \ | pogreška' / var / log / *.zapisnik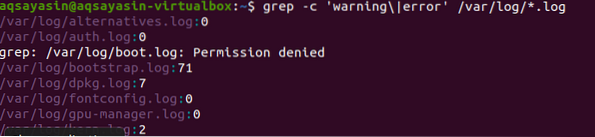
Ova naredba podrazumijeva da će se datoteke pretraživati u svim datotekama .nastavak dnevnika. U rezultatu će se prikazati broj podudaranja kako bi se bolje demonstrirao grep s određenim nastavkom datoteke.
U drugom primjeru upotrijebili smo dvije riječi u našim datotekama na Linuxu s proširenjem teksta. Svi podaci bit će prikazani u obliku brojeva. 0 označava da nema podudarnih podataka, dok drugo osim 0 pokazuje da podudaranje postoji.
$ grep -c 'aqsa \ | my' / home / aqsayasin / *.txt
Rekurzivno pretraživanje više uzoraka u datoteci
Prema zadanim postavkama koristi se trenutni direktorij ako u naredbi nije naveden direktorij. Ako želite pretraživati u direktoriju po vlastitom izboru, onda ga morate spomenuti. Operator "-r" koristi se za grep rekurzivno./ home / aqsayasin / prikazuje put do datoteka, dok *.txt prikazuje proširenje. Tekstualne datoteke bit će cilj grepa za rekurzivno pretraživanje.
$ grep -R 'tehničko \ | besplatno' / home / aqsayasin / *.txt
Željeni izlaz istaknut je u rezultatu koji pokazuje postojanje ovih riječi.
Zaključak
U gore spomenutom članku citirali smo različite primjere kako bismo korisniku olakšali razumijevanje rada naredbi za pretraživanje višestrukih uzoraka na Linuxu. Ovaj vodič pomoći će vam u eskalaciji vašeg postojećeg znanja.


