Apache Kafka
Za definiciju na visokoj razini, predstavimo kratku definiciju za Apache Kafka:
Apache Kafka je distribuirani dnevnik pogrešaka, tolerantan na pogreške, vodoravno skalirajući.
To su bile neke riječi na visokoj razini o Apacheu Kafki. Razumijemo pojmove ovdje detaljno.
- Distribuirano: Kafka dijeli podatke koje sadrži na više poslužitelja i svaki od tih poslužitelja sposoban je obrađivati zahtjeve klijenata za udio podataka koje sadrži
- Otporan na greške: Kafka nema niti jednu točku neuspjeha. U SPoF sustavu, poput MySQL baze podataka, ako poslužitelj koji hostira bazu podataka padne, aplikacija je zeznuta. U sustavu koji nema SPoF i sastoji se od više čvorova, čak i ako se veći dio sustava sruši, to je i dalje isto za krajnjeg korisnika.
- Horizontalno skalabilno: Ova vrsta skaliranja odnosi se na dodavanje više strojeva postojećem klasteru. To znači da je Apache Kafka sposoban prihvatiti više čvorova u svom klasteru i ne osigurati vrijeme prestanka rada za potrebne nadogradnje sustava. Pogledajte donju sliku da biste razumjeli vrstu skalirajućih koncepata:
- Zapis dnevnika: Dnevnik predavanja je Struktura podataka baš poput povezanog popisa. Dodaje poruke koje mu dolaze i uvijek održava njihov red. Podaci se ne mogu izbrisati iz ovog dnevnika dok se za te podatke ne dosegne određeno vrijeme.
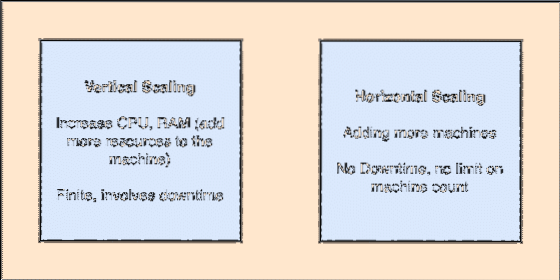
Okomito i vodoravno skaliranje
Tema u Apache Kafki je poput redova u kojem se pohranjuju poruke. Te se poruke pohranjuju podesivo vrijeme i poruka se ne briše dok se to vrijeme ne postigne, čak iako su je potrošili svi poznati potrošači.
Kafka je skalabilan jer su potrošači ti koji zapravo pohranjuju ono što su oni zadnji puta dohvatili kao "offset" vrijednost. Pogledajmo sliku kako bismo ovo bolje razumjeli: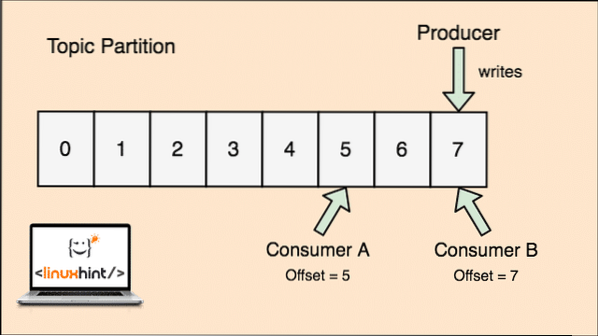
Dio teme i potrošački pomak u Apache Kafki
Početak rada s Apacheom Kafkom
Da biste počeli koristiti Apache Kafka, mora biti instaliran na stroju. Da biste to učinili, pročitajte Instalacija Apache Kafke na Ubuntuu.
Provjerite imate li aktivnu instalaciju Kafke ako želite isprobati primjere koje ćemo predstaviti kasnije u lekciji.
Kako radi?
S Kafkom, Proizvođač prijave objaviti poruke koja stiže do Kafke Čvor a ne izravno potrošaču. Iz ovog Kafka čvora poruke troši Potrošač aplikacije.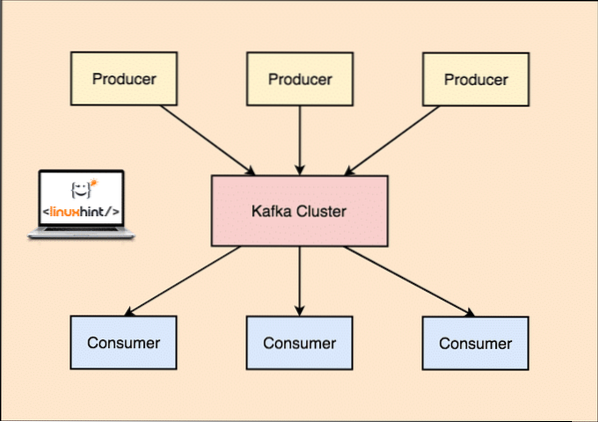
Kafka proizvođač i potrošač
Kako jedna tema može dobiti puno podataka odjednom, kako bi Kafka bila vodoravno skalabilna, svaka je tema podijeljena na pregrade i svaka particija može živjeti na bilo kojem čvornom stroju klastera. Pokušajmo to predstaviti:
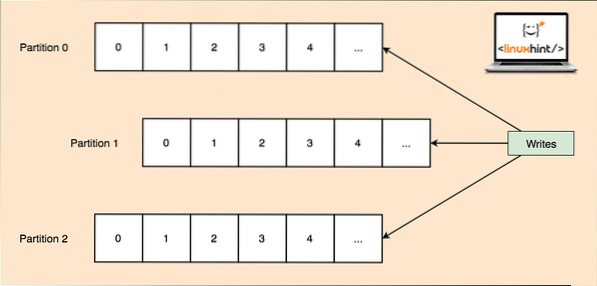
Tematske particije
Opet, Kafka Broker ne vodi evidenciju o tome koji je potrošač potrošio koliko paketa podataka. To je ono odgovornost potrošača za praćenje podataka koje je potrošila.
Postojanost na disku
Kafka nastavlja zapise poruka koje dobiva od proizvođača na disku i ne čuva ih u memoriji. Pitanje koje bi se moglo postaviti jest kako to stvari čini izvedivima i brzima? Iza ovoga je bilo nekoliko razloga koji ga čine optimalnim načinom upravljanja zapisima poruka:
- Kafka slijedi protokol grupiranja zapisa poruka. Proizvođači proizvode poruke koje se ustraju na disku velikim komadima, a potrošači te zapise poruka troše i u velikim linearnim komadima.
- Razlog zašto su upisivanja na disk linearna je taj što to brzo čini čitanje zbog jako smanjenog vremena čitanja linearnog diska.
- Linearne diskovne operacije optimizirane su pomoću Operativni sustavi kao i pomoću tehnika pisanje iza i čitanje unaprijed.
- Suvremeni OS također koriste koncept Predmemoriranje stranica što znači da neke podatke s diska spremaju u besplatnu dostupnu RAM memoriju.
- Kako Kafka zadržava podatke u jedinstvenim standardnim podacima u cijelom toku od proizvođača do potrošača, koristi se optimizacija nulte kopije postupak.
Distribucija i replikacija podataka
Kao što smo gore proučavali da je tema podijeljena na particije, svaki se zapis poruke replicira na više čvorova klastera kako bi se održao redoslijed i podaci svakog zapisa u slučaju da jedan od čvorova umre.
Iako se particija replicira na više čvorova, još uvijek postoji vođa podjele čvor preko kojeg aplikacije čitaju i zapisuju podatke o temi, a voditelj replicira podatke na drugim čvorovima, koji se nazivaju sljedbenici te pregrade.
Ako su podaci zapisa poruke izuzetno važni za aplikaciju, jamstvo da će zapis poruke biti siguran u jednom od čvorova može se povećati povećanjem faktor replikacije klastera.
Što je čuvar zoološkog vrta?
Zookeeper je distribuirana trgovina ključeva i vrijednosti vrlo otporna na kvarove. Apache Kafka u velikoj mjeri ovisi o čuvaru zooloških vrtova za pohranu mehanike klastera poput otkucaja srca, distribucije ažuriranja / konfiguracija itd.).
Omogućuje Kafkinim posrednicima da se pretplate i znaju kad god se dogodi bilo kakva promjena u vezi s vođom particije i distribucijom čvorova.
Aplikacije proizvođača i potrošača izravno komuniciraju sa Zookeeperom aplikacija da zna koji je čvor voditelj particije za temu kako bi mogli izvoditi čitanje i pisanje s voditelja particije.
Strujanje
Procesor strujanja glavna je komponenta u Kafka klasteru koja uzima kontinuirani tok podataka zapisa poruka od ulaznih tema, obrađuje te podatke i stvara tok podataka za izlaz teme koji mogu biti bilo što, od smeća do baze podataka.
Potpuno je moguće izvesti jednostavnu obradu izravno pomoću API-ja proizvođača / potrošača, iako za složenu obradu, poput kombiniranja streamova, Kafka nudi integriranu biblioteku Streams API, ali imajte na umu da je ovaj API namijenjen korištenju u našoj vlastitoj bazi koda i ne ' ne trči na brokeru. Djeluje slično potrošačkom API-ju i pomaže nam da proširimo rad obrade toka u više aplikacija.
Kada koristiti Apache Kafka?
Kao što smo proučavali u gornjim odjeljcima, Apache Kafka može se koristiti za rješavanje velikog broja zapisa poruka koji mogu pripadati gotovo beskonačnom broju tema u našim sustavima.
Apache Kafka idealan je kandidat za upotrebu usluge koja nam može omogućiti da u našim aplikacijama pratimo arhitekturu vođenu događajima. To je zbog njegovih mogućnosti postojanosti podataka, otporne na greške i visoko distribuirane arhitekture gdje se kritične aplikacije mogu pouzdati u njegove performanse.
Skalabilna i distribuirana arhitektura Kafke čini integraciju s mikrouslugama vrlo jednostavnom i omogućuje aplikaciji da se razdvoji s puno poslovne logike.
Stvaranje nove teme
Možemo stvoriti testnu temu testiranje na Apache Kafka poslužitelju sljedećom naredbom:
Stvaranje teme
sudo kafka-teme.sh --create --zookeeper localhost: 2181 - faktor replikacije 1--particije 1 - tematsko ispitivanje
Evo što vraćamo ovom naredbom: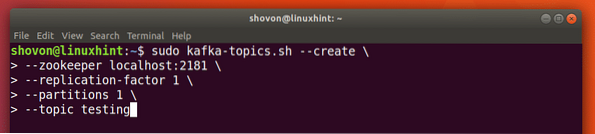
Stvori novu Kafkinu temu
Stvorit će se testna tema koju možemo potvrditi spomenutom naredbom:
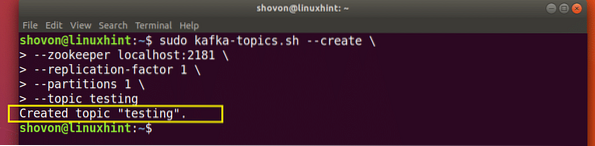
Potvrda stvaranja teme Kafka
Pisanje poruka na temu
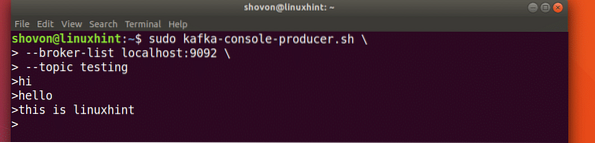
Kao što smo ranije proučavali, jedan od API-ja prisutan u Apache Kafki je API proizvođača. Koristit ćemo ovaj API za stvaranje nove poruke i objavljivanje u temi koju smo upravo kreirali:
Pisanje poruke temi
sudo kafka-proizvođač konzola.sh --broker-list localhost: 9092 - tematsko testiranjePogledajmo izlaz za ovu naredbu:
Objavi poruku Kafki Topic
Jednom kada pritisnemo tipku, vidjet ćemo novu strelicu (>) što znači da sada možemo unositi podatke:

Utipkavanje poruke
Samo unesite nešto i pritisnite da biste započeli novi redak. Utipkao sam 3 retka teksta:
Čitanje poruka iz teme
Sad kad smo objavili poruku o temi Kafka koju smo stvorili, ova će poruka biti prisutna neko vrijeme koje se može konfigurirati. Sad ga možemo pročitati pomoću Potrošački API:
Čitanje poruka iz teme
sudo kafka-konzola-potrošač.sh --čuvar lokalnog domaćina: 2181 --ispitivanje teme - od početka
Evo što vraćamo ovom naredbom:
Naredba za čitanje poruke Kafke Topića
Moći ćemo vidjeti poruke ili retke koje smo napisali pomoću API-ja proizvođača, kao što je prikazano dolje:
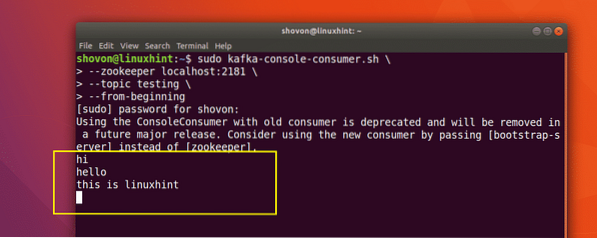
Ako napišemo još jednu novu poruku pomoću API-ja proizvođača, ona će se također odmah prikazati na strani Potrošač:
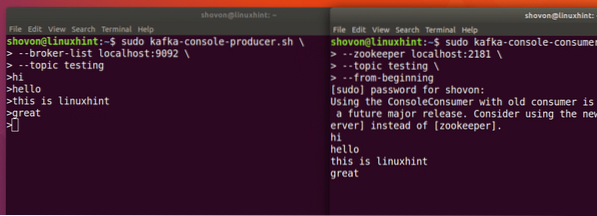
Objavite i potrošite istovremeno
Zaključak
U ovoj smo lekciji pogledali kako počinjemo koristiti Apache Kafka koji je izvrstan posrednik poruka, a može djelovati i kao posebna jedinica za trajnost podataka.


