Veliki podaci su podaci reda terabajta ili petabajta i dalje, koji se sastoje od rudarstva, analize i prediktivnog modeliranja velikih skupova podataka. Brzi rast informacijskog i tehnološkog razvoja pružio je jedinstvenu priliku za pojedince i poduzeća širom svijeta da ostvare dobit i razviju nove sposobnosti redefinirajući tradicionalne poslovne modele koristeći veliku analitiku.
Ovaj članak pruža pogled iz ptičje perspektive na pet najpopularnijih platformi s otvorenim kodom podataka. Evo našeg popisa:
Apache Hadoop
Apache Hadoop je softverska platforma otvorenog koda koja obrađuje vrlo velike skupove podataka u distribuiranom okruženju s obzirom na pohranu i računsku snagu, a uglavnom se gradi na jeftinom robnom hardveru.
Apache Hadoop dizajniran je za jednostavno skaliranje s nekoliko na tisuće poslužitelja. Pomaže vam u obradi lokalno pohranjenih podataka u cjelokupnoj postavci paralelne obrade. Jedna od prednosti Hadoopa je ta što rješava kvarove na softverskoj razini. Sljedeća slika ilustrira cjelokupnu arhitekturu ekosustava Hadoop i gdje su unutar njega različiti okviri:
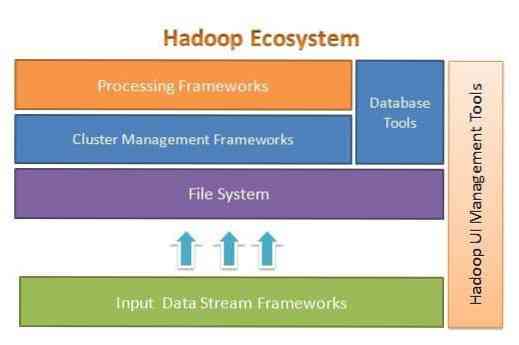
Apache Hadoop pruža okvir za sloj datotečnog sustava, sloj upravljanja klasterom i sloj obrade. Ostavlja mogućnost drugim projektima i okvirima da dođu i rade zajedno s Hadoop ekosustavom i razviju vlastiti okvir za bilo koji sloj dostupan u sustavu.
Apache Hadoop sastoji se od četiri glavna modula. Ti su moduli Hadoop distribuirani datotečni sustav (sloj datotečnog sustava), Hadoop MapReduce (koji radi i s upravljanjem klasterom i s slojem obrade), Još jedan pregovarač o resursima (YARN, sloj upravljanja klasterom) i Hadoop Common.
Elasticsearch
Elasticsearch je cjeloviti tekstualni pretraživač i analitičar. To je visoko skalabilan i distribuiran sustav, posebno dizajniran za učinkovit i brz rad sa sustavima velikih podataka, gdje je jedan od njegovih glavnih slučajeva uporabe analiza dnevnika. Sposoban je izvoditi napredna i složena pretraživanja te gotovo u stvarnom vremenu obrađivati naprednu analitiku i operativnu inteligenciju.
Elasticsearch napisan je na Javi, a temelji se na Apache Luceneu. Objavljen 2010. godine i brzo je stekao popularnost zbog fleksibilne strukture podataka, skalabilne arhitekture i vrlo brzog vremena odziva. Elasticsearch temelji se na JSON dokumentu sa strukturom bez sheme, čineći usvajanje lakim i bez muke. Jedna je od najvažnijih tražilica poslovnog razreda. Možete napisati njegovog klijenta na bilo kojem programskom jeziku; Elasticsearch službeno radi s Javom, .NET, PHP, Python, Perl itd.
Elasticsearch uglavnom komunicira koristeći REST API. Dobija podatke u obliku JSON dokumenata sa svim potrebnim parametrima i daje svoj odgovor na sličan način.
MongoDB
MongoDB je NoSQL baza podataka koja se temelji na modelu podataka pohrane dokumenata. U MongoDB-u je sve ili zbirka ili dokument. Da bi se razumjela MongoDB terminologija, zbirka je zamjenska riječ za tablicu, dok je dokument zamjenska riječ za retke.
MongoDB je baza podataka otvorenog koda, orijentirana na dokumente i više platformi. Prvenstveno je napisan na C++. Također je vodeća NoSQL baza podataka koja pruža visoke performanse, visoku dostupnost i jednostavnu skalabilnost. MongoDB koristi JSON-slične dokumente sa shemom i pruža bogatu podršku za upite. Neke od glavnih značajki uključuju indeksiranje, replikaciju, uravnoteženje opterećenja, agregiranje i pohranu datoteka.
Cassandra
Cassandra je Apache projekt otvorenog koda dizajniran za upravljanje bazama podataka NoSQL. Redovi Cassandre organizirani su u tablice i indeksirani ključem. Koristi dodatak, mehanizam za pohranu zasnovan na zapisnicima. Podaci u Cassandri distribuiraju se kroz više čvorova bez master-a, bez ijedne točke kvara. Riječ je o vrhunskom Apache projektu, a njegov razvoj trenutno nadgleda Apache Software Foundation (ASF).
Cassandra je dizajnirana za rješavanje problema povezanih s radom u velikim (web) razmjerima. S obzirom na Cassandrinu arhitekturu bez majstora, sposobna je nastaviti izvoditi operacije usprkos malom (iako značajnom) broju hardverskih kvarova. Cassandra prolazi preko više čvorova u više podatkovnih centara. Replicira podatke u tim podatkovnim centrima kako bi izbjegao kvarove ili zastoje. To ga čini izuzetno podnošljivim sustavom.
Cassandra koristi vlastiti programski jezik za pristup podacima preko svojih čvorova. Zove se Cassandra Query Language ili CQL. Sličan je SQL-u, koji uglavnom koriste relacijske baze podataka. CQL se može koristiti pokretanjem vlastite aplikacije nazvane cqlsh. Cassandra također nudi mnoga integracijska sučelja za više programskih jezika za izgradnju aplikacije pomoću Cassandre. Njegov integracijski API podržava Java, C ++, Python i druge.
Apache HBase
HBase je još jedan Apacheov projekt osmišljen za upravljanje NoSQL pohranom podataka. Dizajniran je da koristi značajke Hadoop ekosustava, uključujući pouzdanost, toleranciju kvarova i tako dalje. Za pohranu koristi HDFS kao sustav datoteka. Postoji više podatkovnih modela s kojima NoSQL radi, a Apache HBase pripada podatkovnom modelu orijentiranom na stupac. HBase se izvorno temeljio na Google Big Table, koji je također povezan s modelom orijentiranim na stupac za nestrukturirane podatke.
HBase pohranjuje sve u obliku para ključ / vrijednost. Važno je napomenuti da su u HBaseu ključ i vrijednost u obliku bajtova. Dakle, da biste pohranili bilo kakve podatke u HBase, morate ih pretvoriti u bajtove. (Drugim riječima, njegov API ne prihvaća ništa osim bajt polja.) Budite oprezni s HBaseom, jer kad spremate podatke, trebali biste se sjetiti njihove izvorne vrste. Podaci koji su izvorno bili niz vratit će se kao bajtni niz ako se pogrešno opozovu. Kao rezultat, stvorit će bug u vašoj aplikaciji i srušiti vaš program.
Nadam se da vam se svidio ovaj članak. Ako želite dizajnirati i dizajnirati podatkovno zahtjevne aplikacije, tada možete istražiti Anuja Kumara Arhitektura podataka intenzivnih aplikacija. Ovaj knjiga je vaš pristupnik za izgradnju pametnih podatkovno intenzivnih sustava ugrađivanjem osnovnih podatkovno intenzivnih arhitektonskih principa, obrazaca i tehnika izravno u vašu arhitekturu aplikacija.


